ビットフィールド
ビット単位での値の管理
メモリ上のデータは1バイト単位で管理されていますが、デジタルでの最小単位は1ビットです。
1バイトは(大抵の環境では)8ビットのデータです。
C言語での最小のデータ型はchar型の1バイトです。
1バイトは256通りのデータが扱えますが、例えば0~10の範囲で十分なことが確実なデータの場合、4ビットあれば十分ということになります。
(2の4乗=16)
こういったデータでも通常はchar型を使用しますが、残りの4ビットは常に使用されない、ということになります。
ビットフィールドを使用すれば、この残りの4ビットのメモリ領域に別のデータを割り当てることができます。
ビットフィールドの動作は環境に依存する部分が大きく、移植性に難があります。
また、上手く使用すればメモリの節約になりますが、その引き換えとして実行効率があまりよくないことが多いそうです。
近年のパソコンやスマホなどはメモリが潤沢なので、そこまでメモリ効率は重視されません。
そのため、ビットフィールドはあまり使用されていないようです。
ビットフィールドは構造体を使用して定義します。
#include <stdio.h>
//ビットフィールド
typedef struct {
unsigned int b0 : 4;
unsigned int b1 : 4;
} BitSample;
int main()
{
BitSample bitSample = { 0 };
bitSample.b0 = 5;
bitSample.b1 = 10;
printf("b0: %d\n", bitSample.b0);
printf("b1: %d\n", bitSample.b1);
getchar();
}
b0: 5 b1: 10
構造体のメンバ名の後に「:数値」を記述することで、そのメンバはビットフィールドとして働きます。
数値は使用するビット数の指定です。
データ型の指定は今回はunsigned intを指定しています。
これについては後述します。
使用方法は構造体と同じで、.でメンバであるビットフィールドにアクセスできます。
ポインタで扱う場合は->でアクセスできます。
上記サンプルコードでは各ビットフィールドに4ビットずつ割り当てています。
4ビットは0~15の範囲のデータなので、それ以上の値を代入するとオーバーフローが発生します。
(符号なし型なので値は一巡します)
bitSample.b0 = 15;
bitSample.b1 = 16;
printf("b0: %d\n", bitSample.b0);
printf("b1: %d\n", bitSample.b1);
b0: 15 b1: 0
通常のメンバとの共存
ビットフィールドは構造体の機能のひとつという位置づけで、通常のメンバとビットフィールドとなるメンバとを共存させることもできます。
typedef struct {
char str[20];
int num;
unsigned int bf0 : 4;
unsigned int bf1 : 4;
} BitSample;
データ型
データ型の指定はintやshortなどの組み込み型が使用できます。
構造体などのユーザー定義型は使用できません。
ちなみにビットフィールドにおいて「int」の指定は処理系依存になるそうです。
本来であればintは符号あり整数ですが、ビットフィールドでは「符号あり」になるか「符号なし」になるかは不定ということです。
なので、int型を指定する場合はsigned/unsignedを指定するのが無難です。
typedef struct {
signed b0 : 4;
unsigned b1 : 4;
} BitSample;
コード中にunsignedとだけ記述した場合はunsigned intと解釈されます。
signedの場合も同様に、signed intと解釈されます。
これはビットフィールドに限った話ではなく、通常の変数宣言でも同様です。
ビットフィールドのサイズは数値指定で行うため、データ型で指定したサイズは影響しません。
データ型は構造体変数のサイズに影響します。
#include <stdio.h>
typedef struct {
unsigned char b0 : 1;
} BitA;
typedef struct {
unsigned short b0 : 1;
} BitB;
typedef struct {
unsigned int b0 : 1;
} BitC;
typedef struct {
unsigned long long b0 : 1;
} BitD;
int main()
{
printf("BitA: %d\n", sizeof(BitA));
printf("BitB: %d\n", sizeof(BitB));
printf("BitC: %d\n", sizeof(BitC));
printf("BitD: %d\n", sizeof(BitD));
getchar();
}
BitA: 1 BitB: 2 BitC: 4 BitD: 8
この実行結果はWindows + Visual Studio環境の場合です。
他の環境では異なる可能性があります。
メモリ上のデータの保存は1バイト単位であるため、メンバが1ビットひとつのビットフィールドであってもメモリ上の保存サイズが1バイト未満になることはありません。
また、データ型が持つビット数以上の数値を指定してビットフィールドを作ることはできません。
(int型なら32まで)
メモリ上のデータ配置について
例えば以下のようなビットフィールドについて、何バイト必要かを考えてみます。
#include <stdio.h>
typedef struct {
unsigned b0 : 4;
unsigned b1 : 16;
unsigned b2 : 16;
unsigned b3 : 28;
} BitSampleA;
typedef struct {
unsigned b0 : 16;
unsigned b1 : 16;
unsigned b2 : 28;
unsigned b3 : 4;
} BitSampleB;
int main()
{
printf("BitSampleA: %d\n", sizeof(BitSampleA));
printf("BitSampleB: %d\n", sizeof(BitSampleB));
getchar();
}
順番が違うだけでどちらも合計で64ビットなので、8バイトあれば足りることになります。
しかしこれをWindows + Visual Studio環境で実行すると以下のようになります。
BitSampleA: 12 BitSampleB: 8
これは以下のようにメモリ上にデータが配置されていると考えられます。
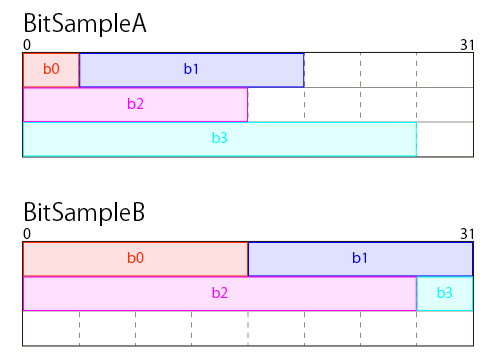
0~31というのはint型ひとつ分のビットのサイズです。
前述の通り、Visual Studioではint型でビットフィールドを作ると32ビット(4バイト)単位でメモリ上の領域が確保されます。
これを記憶域単位といいます。
BitSampleAのほうは、b0とb1がメモリに配置された時点でまだ12ビットの余りがあります。
次のb2のサイズは16ビットなので、ここに配置すると4ビットがはみ出すことになります。
この環境では記憶域単位にまたがってデータを配置することはせず、足りない場合は次の記憶域単位にデータを割り当てるようです。
BitSampleBのほうは記憶域単位をまたがる配置がないため、BitSampleAよりもサイズが4バイト小さくなっています。
これはあくまでもWindows + Visual Studio環境の場合の話で、C言語ではどのようにビットデータを配置するかの取り決めはありません。
記憶域単位をまたがる配置をする環境もあり得ます。
また、上図はメモリの下位(0のほう)から順にデータを配置していますが、これについての取り決めもありません。
なお、ビットフィールドはアドレスを取得できません。
(アドレスはバイト単位のメモリ上の位置だから)
なので、ビットフィールドをポインタで扱うことはできません。
名前なしビットフィールド
ビットフィールドはメンバ名を省略することができます。
typedef struct {
unsigned b0 : 24;
unsigned b1 : 6;
unsigned : 2; //名前なしビットフィールド
unsigned b2 : 16;
} BitSample;
名前がないので、そのメンバにはアクセスすることはできません。
しかし指定したメモリ領域は確保されます。
これはビットの配置を明示的に行う場合に利用されます。
上のコードならば、b1の時点で記憶域単位に30ビット分データが確保されています。
次の名前なしビットフィールドで2ビット確保されるので、記憶域単位がちょうど32ビットで埋まります。
次のb2は新しい記憶域単位にデータが配置されます。
b2のサイズは記憶域単位の余りよりも大きいので、前述のとおりVisual Studioならばこの指定がなくとも新しい記憶域単位が使用されますが、他のコンパイラではどうなるかはわかりません。
記憶域単位の途中へのアクセスよりも先頭へのアクセスのほうが高速に行えるので、このようなデータの指定方法が存在します。
サイズが0のビットフィールド
名前なしビットフィールドは、そのサイズに0を指定することができます。
typedef struct {
unsigned b0 : 1;
unsigned : 0; //ゼロサイズ
unsigned b1 : 1;
} BitSampleA;
typedef struct {
unsigned b0 : 1;
unsigned b1 : 1;
} BitSampleB;
BitSampleA: 8 BitSampleB: 4
サイズに0を指定すると、次のビットフィールドのメモリの確保は強制的に新しい記憶域単位に割り当てられるようになります。
これもデータ配置を明示的に行うための機能です。
ビットフィールドでフラグ管理
ビット演算の活用法の項では、ビット演算を使用してchar型変数ひとつで8つのフラグを管理する方法を紹介しました。
これと同じことをビットフィールドで実現することができます。
#include <stdio.h>
typedef struct {
unsigned char b0 : 1;
unsigned char b1 : 1;
unsigned char b2 : 1;
unsigned char b3 : 1;
unsigned char b4 : 1;
unsigned char b5 : 1;
unsigned char b6 : 1;
unsigned char b7 : 1;
} Bitfield8;
int main()
{
Bitfield8 bf8 = { 0 };
//各メンバで独立したフラグ管理が可能
bf8.b0 = 0;
bf8.b1 = 1;
bf8.b2 = 0;
bf8.b3 = 1;
printf("%d\n", bf8.b0);
printf("%d\n", bf8.b1);
printf("%d\n", bf8.b2);
printf("%d\n", bf8.b3);
getchar();
}
0 1 0 1
ビット演算は見た目が分かりづらいという欠点がありますが、ビットフィールドは見た目通りの処理が可能です。
ただし処理速度はビット演算のほうが優れているようです。