ポインタと配列
配列の先頭要素へのポインタ
ポインタと配列は別物ですが、ちょっとした関係性があります。
まずは以下のコードを見てください。
#include <stdio.h>
int main()
{
int arr[] = { 11, 22, 33, 44 };
int *pointer;
pointer = arr; //配列の先頭要素のポインタ取得
printf("%d\n", *pointer); //先頭要素の値を表示
pointer = &(arr[0]); //↑と同じ
printf("%d\n", *pointer);
pointer += 1; //arr[1]と同じ
printf("%d\n", *pointer);
getchar();
}
11 11 22
8行目、ポインタ変数pointerに配列を代入しています。
配列の名前の後にいつもの角括弧[](添字演算子)が付けられておらず、配列名をそのまま指定しています。
配列は、配列名のみを記述すると配列の先頭要素へのポインタを返すという決まりがあります。
配列の先頭要素のポインタなので、そのままポインタ変数に代入できますし、ポインタ変数pointerの値を表示するとちゃんと「11」が表示されます。
11行目、今度はいつも通り添字演算子をつかって先頭要素(0番目)を指定した上で、アドレス演算子を使ってアドレスを取り出しています。
これは8行目と同じ意味になるので、やはり値は「11」になります。
14行目では、ポインタ変数pointerに「1」を加算しています。
配列の要素を示すポインタ変数に値をひとつ加算すると、指し示す先が配列の次の要素に移動するという特徴があります。
つまりこれは、arr[1]と同じ位置を指すことになります。

配列の各要素は、メモリ上の連続した位置に順に配置されることが保証されています。
配列の先頭要素のアドレスの次のアドレスは、その配列の二番目の要素というわけです。
ただし、この図は実は正確ではありません。
「次の要素のアドレス」の具体的な位置は、ポインタ変数のデータ型により異なるためです。
ポインタの型とポインタ演算
ポインタ変数に加算や減算等の演算を行い、指し示す先を変更することをポインタ演算と言います。
配列の要素を示すポインタ変数に1加算すると、配列の次の要素を指します。
これは「ポインタ変数に1を加算するとアドレスが1増える」ではないことに注意してください。
変数にはデータ型があります。
データ型が異なると、その値を保存するためのメモリ上のサイズが異なります。
char型ならば1バイト、short型ならば2バイトのメモリ上の領域が必要になります。
今までの図では簡略化していましたが、実際にはこのようになります。
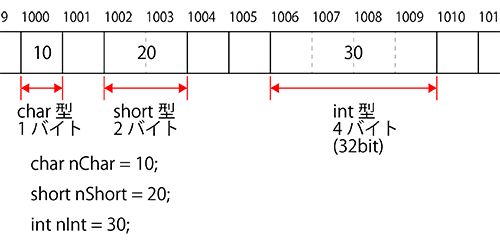
ポインタ変数は、メモリ上の場所(アドレス)の情報だけではなく、データ型も記憶しています。
例えばint *pointerならば「メモリ上の場所は○○で、そこでは4バイト消費している」という情報を持っていることになります。
(int型のサイズは環境によって異なります。ここでは32bit(=4バイト)を前提に進めます)
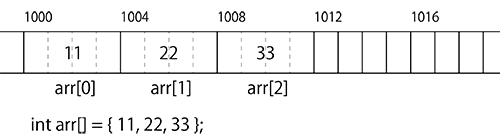
int型配列を宣言した時、メモリ上には4バイトごとに連続した位置に値が配置されます。
(本当かどうか気になる人は確認プログラムを作ってみてください)
配列の先頭要素のアドレスが「1000」であるとき、先頭要素を指すポインタ変数に「1」を加算すると、そのポインタ変数が保存するアドレスは「1004」になります。
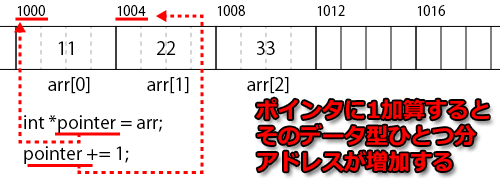
つまり、ポインタ変数の演算時に実際に増減する値は「増減させたい値×データ型サイズ」である、ということです。
これはインクリメント/デクリメントの場合でも同様です。
int arr[] = { 11, 22, 33, 44 };
int *pointer;
pointer = arr;
//次の要素を指す
//つまりアドレスにプラス4バイト
pointer++;
//前の要素を指す
//つまりアドレスにマイナス4バイト
pointer--;
ポインタ変数のサイズ
「ポインタ変数自体のサイズ」はデータ型が変わっても同じです。
char型へのアドレスでもlong long型へのアドレスでも、ポインタ変数ひとつを使用するために消費するメモリサイズは変わりません。
この性質は、巨大なデータを高速に処理する場合に役に立つことがあります。
#include <stdio.h>
int main()
{
printf("sizeof(char) = %u, sizeof(char*) = %u\n",
sizeof(char), sizeof(char*));
printf("sizeof(int) = %u, sizeof(int*) = %u\n",
sizeof(int), sizeof(int*));
printf("sizeof(long long) = %u, sizeof(long long*) = %u\n",
sizeof(long long), sizeof(long long*));
getchar();
}
sizeof(char) = 1, sizeof(char*) = 4 sizeof(int) = 4, sizeof(int*) = 4 sizeof(long long) = 8, sizeof(long long*) = 4
32bit環境ではポインタのサイズは32bit、つまり4バイトです。
64bit環境ではポインタサイズは64bit、つまり8バイトです。
void*型
ポインタ変数にはvoid*型という特殊なデータ型が存在します。
voidは「空(から)」という意味ですが、ポインタの型として使用すると「アドレスのみを保存するポインタ」となります。
つまり指し示す先で使用しているメモリのサイズ情報は持ちません。
void*型は例えばファイルなどの「あらかじめサイズが分からないデータ」を読み書きする関数で使用されるデータ型です。
そのままvoid*型で受け取ることもできますが、void*型はサイズが分からないのでポインタ演算はできません。
1バイトずつ処理する場合はchar*型、フォーマット(データの構造)が決まっているならば目的のデータ型のポインタ型にキャストして受け取ることが多いです。
long long num = 123456789;
//void*型に変換
void* pointer = (void*)#
printf("%08x\n", pointer); //アドレス表示
//char*型に変換
signed char* pc = (signed char*)pointer;
signed char c = *pc;
pc++; //1バイト進める
//short*型に変換
short* ps = (short*)pc;
short s = *ps;
ps++; //2バイト進める
//int*型に変換
int* pi = (int*)ps;
int l = *pi;
pi++; //4バイト進める
//void*型に戻す
pointer = (void*)pi;
printf("%08x\n", pointer); //アドレス表示
0113fa48 0113fa4f
上記はlong long型(8バイト)のメモリ領域を「signed char*型」「short*型」「int*型」に分割して値を受け取っています。
全部で7バイトなので、最終的に7バイト分メモリが進められています。
(「8 + 7 = 15」、15は16進数で「f」)
もちろんこのような値の読み取り方をしても通常は意味のある値にはなりません。
ポインタの配列的な記述
以下のコードは一見奇妙に見えるかもしれませんが、有効なコードです。
#include <stdio.h>
int main()
{
int arr[] = { 11, 22, 33, 44 };
int *pointer;
pointer = arr;
for (int i = 0; i < 4; i++)
{
printf("%d\n", pointer[i]);
//printf("%d\n", *(pointer + i));
}
getchar();
}
pointerはint型ポインタ変数として宣言していますが、11行目のprintf関数内ではポインタ変数に対して角括弧[]を使用しています。
このpointer[i]は*(pointer + i)と同じ意味となります。
//以下の二つは全く同じ
*(pointer + 1);
pointer[1];
//これは意味が変わるので注意
//(ポインタが指す値に1を加算)
*pointer + 1;
添字演算子は配列にしか指定できないわけではなく、その機能は「ポインタ+添え字」の位置の値へアクセスする、というものです。
配列名のみを記述した場合は配列の先頭要素へのアドレスを得られますから、arr[3]は*(arr + 3)に自動的に変換されるというわけです。
実は3[arr]のように、配列名と添え字とを逆に書いてもエラーにはなりません。
*(3 + arr)に変換されるだけで演算結果は変わらないからです。
(ややこしいので普通はこんな書き方はしませんが)
関数の仮引数の配列
上記の変換ルールは関数の引数に配列を指定する場合によく利用されています。
例えば以下のようなコードです。
#include <stdio.h>
double average(const int arr[], int length)
{
if (length <= 0)
return 0.0;
int total = 0;
for (int i = 0; i < length; i++)
{
total += arr[i];
}
return (double)total / length;
}
int main()
{
int numbers[] = { 60, 75, 82 };
printf("%f", average(
numbers,
sizeof(numbers) / sizeof(numbers[0])));
getchar();
}
これは配列と関数の項で使用したサンプルコードと全く同じものです。
const int arr[]で引数に配列を指定しているのですが、これは実は内部的にconst int *arrに置き換えられています。
double average(const int arr[], int length)
{
}
//↓
double average(const int *arr, int length)
{
}
角括弧を用いた引数の記述は、ポインタとして記述したのとまったく同じ意味になります。
渡されるのは配列ではないので、角括弧内に要素数を指定しても無視されます。
11行目のtotal += arr[i]というコードも、実際にはtotal += *(arr + i)と記述したのと同じことです。
配列と関数の項では、知らないうちにポインタを利用していたことになります。
「*(ポインタ変数 + n)」という書き方よりも「ポインタ変数[n]」という配列的な書き方の方がコードの意味がわかりやすいため、このような書き方が許されています。
このような、特定の操作を簡便な記述で行えるようにする言語側のサポートをシンタックスシュガー(糖衣構文)と言います。
配列が関数内で書き換えられる理由
このことが分かれば、配列と関数の項の最後で紹介した「配列は関数の引数に指定すると関数内で書き換えられる」という理由が分かります。
関数に配列を渡したつもりでも、実際に渡されていたのは配列自身ではなく「配列の先頭要素を示すポインタ」です。
関数の呼び出し側の実引数に角括弧を付けないのも、配列の先頭要素のアドレスを渡していたからです。
//int Func(int arr[], int length)
//↑の宣言は↓と同じ
int Func1(int arr*, int length)
{
//引数arrはint*型のポインタ変数なので
//指し示す先の値を書き換えると
//関数呼び出し元の値も書き換わる
}
int Func2(const int arr*, int length)
{
//引数arrはconst int*型なので
//値を書き換えようとするとコンパイルエラー
}
int main()
{
int numbers[] = { 1, 2, 3 };
//配列名のみを指定してアドレスを渡す
Func1(numbers, 3);
}
引数として受け取ったのはポインタですから、ポインタが指し示す先のデータは関数呼び出し元のデータと同じものです。
そのため関数内で値を書き換えると、呼び出し元の値も書き換わります。
関数内で書き換えられたくない場合は引数にconstを指定します。
sizeof演算子で配列サイズを得ることができないのもこのためで、引数で受け取ったのは配列ではなく配列の先頭要素を示すポインタだからです。