共用体
メモリ領域の共有
例えばint型の変数を宣言すれば、その変数専用のメモリ領域が確保されます。
そこにshort型などの値を代入してもint型に暗黙的に型変換されます。
(型変換できない型を代入しようとした場合はエラーになります)
共用体という機能を使うと、ひとつのメモリ領域に複数のデータ型の値を格納できます。
#include <stdio.h>
//共用体
union UnionSample {
int nInt;
short nShort;
char str[10];
};
int main()
{
union UnionSample uni;
uni.nInt = 32768;
printf("nInt: %d\n", uni.nInt);
uni.nShort = 32767;
printf("nShort: %d\n", uni.nShort);
snprintf(uni.str, 10, "%s", "ABC");
printf("str: %s\n", uni.str);
getchar();
}
nInt: 32768 nShort: 32767 str: ABC
共用体の定義はunionというキーワードで行います。
書式は構造体とほとんど同じです。
上のサンプルコードは、メンバに代入した値を表示しているだけなので、これだけでは構造体との違いが無いように思えます。
そこで、各メンバのアドレスを表示してみます。
#include <stdio.h>
struct StructSample {
int nInt;
short nShort;
char str[10];
};
union UnionSample {
int nInt;
short nShort;
char str[10];
};
int main()
{
struct StructSample st;
union UnionSample uni;
printf("構造体\n");
st.nInt = 0;
printf("nInt : %p\n", &st.nInt);
st.nShort = 0;
printf("nShort: %p\n", &st.nShort);
printf("\n共用体\n");
uni.nInt = 0;
printf("nInt : %p\n", &uni.nInt);
uni.nShort = 0;
printf("nShort: %p\n", &uni.nShort);
getchar();
}
構造体 nInt : 004FFC18 nShort: 004FFC1C 共用体 nInt : 004FFC04 nShort: 004FFC04
実際に表示されるアドレスは実行毎に変わります。
構造体のメンバはそれぞれ別のメモリ領域に格納されているので、アドレスは別々となります。
対して共用体は全く同じアドレスが表示されます。
共用体の各メンバは、メモリ上の同じ位置から読み書きを開始します。
メモリ上の同じ場所に保存されるので、共用体の各メンバで有効に使用できるのは最後に値を代入したメンバだけです。
あるメンバへの値の代入は他のすべてのメンバに対するデータの上書きとなります。
あるメンバに値を代入した後、別のメンバからデータを読み取ろうとした場合の動作は環境に依存します。
変数の初期化
共用体は、構造体と同じように変数の宣言と同時に初期化を行うことができます。
union UnionSample {
int nInt;
char str[10];
};
int main()
{
union UnionSample uni = { 123 };
}
共用体では先頭のメンバに対する初期価値のみを記述します。
二番目以降のメンバに対して初期化したい場合は、以下のようにメンバ名を指定して初期化することができます。
union UnionSample uni = { .str = "ABC" };
メンバ名の前に.(ドット)が必要なことに注意してください。
構造体との違いと共通点
構造体は、各メンバの値はメモリ上に順番に配置されていきます。
それらが同じ位置に配置されたり重なりあったりすることはなく、独立しています。
共用体は、各メンバは共用体が確保したメモリ領域の先頭位置から読み書きを行います。
読み書き開始位置が同じなので、あるメンバへの値の書き込みは他のメンバの値を上書き(破壊)します。
それ以外は構造体と共用体はほぼ同じものです。
文法も(使用するキーワードと初期化方法が違う以外は)構造体と共通します。
#include <stdio.h>
union MyUnionA {
int integer;
double real;
};
//typedef
typedef union {
int integer;
double real;
} MyUnionB;
//無名の共用体1
union {
int integer;
double real;
} uniC;
//無名の共用体2
typedef struct {
union {
int integer;
double real;
};
} MyStruct;
int main()
{
union MyUnionA uniA = { 0 };
//typedefにより「union」キーワードが要らなくなる
MyUnionB uniB = { 0 };
MyUnionB* uniP = &uniB;
//ポインタ経由の場合はアロー演算子が使用できる
//int n = (*uniP).integer;
int n = uniP->integer;
MyUnionB uniB2;
//代入で状態をコピーできる
uniB2 = uniB;
//無名の共用体の使用
uniC.integer = 0;
MyStruct st = { 123 };
int n2 = st.integer;
}
共用体のサイズ
共用体のサイズは「一番大きいメンバを格納できるサイズ」となります。
必ずしも最大のメンバのサイズと同じになるわけではなく、末尾にデータサイズ調整のための詰め物(パディングという)がされる可能性もあります。
typedef union {
int nInt;
short nShort;
char str[10];
} UnionSample;
int main()
{
printf("size: %d\n", sizeof(UnionSample));
getchar();
}
size: 12
上記コードをVisual Studioで実行したところ、共用体のサイズは「12」となりました。
最大のサイズのメンバは配列strの「10」ですが、2バイト分の詰め物がされているようです。
共用体の使い道
メモリの節約
共用体はメモリの同じ領域を共有するので、メモリの節約が利用方法としてまず挙げられます。
複数のデータ型をあらかじめ定義しておくことで、それらのいずれかひとつの値を受け取れる変数を作ることができます。
他のプログラミング言語では「バリアント型」という、「どんなデータ型でも入れることが出来る変数」が存在しますが、これに近いことが実現できます。
(ただし自由度は低めです)
#include <stdio.h>
#include <stdlib.h>
#define BUFFER 32
//UserInputが保持するデータ型
typedef enum
{
STRING,
INTEGER,
REAL
} DataType;
//タグ付き共用体
typedef struct {
DataType type;
union {
int integer;
double real;
char str[BUFFER];
};
} UserInput;
//標準入力からmaxLength文字分の文字列を取得してbufに格納
void GetStdInput(char* buf, const unsigned int maxLength)
{
if (maxLength == 0)
return;
char c;
unsigned int count = 0;
while ((c = fgetc(stdin)) != '\n')
{
buf[count++] = c;
if (count >= maxLength) {
count = maxLength - 1;
break;
}
}
buf[count] = '\0';
if (c != '\n') {
while (fgetc(stdin) != '\n');
}
}
//UserInputの内容を表示
void PrintUserInput(const UserInput* input)
{
if (input->type == INTEGER) {
printf("入力値: %d\n", input->integer);
printf("整数値が入力されました\n");
}
else if (input->type == REAL) {
printf("入力値: %f\n", input->real);
printf("小数値が入力されました\n");
}
else {
printf("入力値: %s\n", input->str);
printf("文字列が入力されました\n");
}
}
int main()
{
printf("数値か文字列を入力してください\n");
UserInput input = { 0 };
GetStdInput(input.str, BUFFER);
char* p;
//文字列の数値変換を試みる
//先頭が数値なら変換成功とみなす
//整数型への変換
int n = (int)strtol(input.str, &p, 10);
if (p != input.str && *p != '.') {
input.integer = n;
input.type = INTEGER;
}
else {//小数型への変換
double d = strtod(input.str, &p);
if (p != input.str) {
input.real = d;
input.type = REAL;
}
}
PrintUserInput(&input);
getchar();
}
「整数、小数、文字列のうちどれかひとつだけ必要」というような場合、共用体を使用すれば多少のメモリ節約ができます。
同じことを変数や構造体で行うと、使用されないメモリ領域が必ず発生してしまいます。
上のコードでは構造体の中に共用体を定義&宣言しています。
共用体は「最後に格納したデータ型」を適切に管理する必要があります。
その情報を保存するための変数を用意する場合、別々に管理するのではなく構造体にまとめて保存しておく手法がよく用いられます。
これをタグ付き共用体などと呼びます。
タグ付き共用体は異なるデータ型を配列などでまとめて扱いたい場合にも便利です。
strtol関数、strtod関数は文字列を数値に変換するC言語の標準関数です。
詳しくは文字列を数値に変換の項を参照してください。
別のデータ型への再解釈
共用体のメンバに値を代入した後に、別のメンバからそのデータを読み出すことで、メモリ上に保存されているバイト配列を別のデータ型として扱うことができます。
ただしこの使い方は環境に強く影響されるため、移植性が低いです。
#include <stdio.h>
typedef union {
int num;
char str[4];
} MyUnion;
int main()
{
//文字は内部的に数値で扱われている
int n = 'A';
printf("数値: %d\n", n);
printf("文字: %c\n", n);
printf("\n");
//numを'A'で初期化
MyUnion uni = { 'A' };
//何が表示されるかは環境依存
printf("数値: %d\n", uni.str[0]);
printf("文字: %c\n", uni.str[0]);
getchar();
}
数値: 65 文字: A 数値: 65 文字: A
このコードの実行結果は環境によって変わる可能性があります。
メモリは1バイト単位でデータが保存されています。
int型が4バイトのデータの場合(32bit)、メモリを4マス分確保した上でそこに値を保存します。
この4マスのメモリ領域の中で、どのようにデータを配置するかはOSやハードウェアの環境によって変わります。
このデータの配置方法の種類をバイトオーダーといいます。
例えば以下の16進数の数値は、そのまま番号の若いほうから順番に配置されるとは限りません。
int n = 0x1A2B3C4D;
メモリの上位ビット(番号の若いほう)から順にデータを読み書きする方式をビッグエンディアンといいます。
下位ビットから順に読み書きする方式をリトルエンディアンといいます。
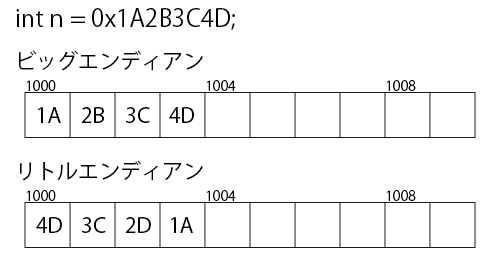
メモリへのデータの配置方式が環境により異なるため、その先頭バイトへアクセスしたときに読み取られるデータも環境によって変わるのです。
typedef union {
int num;
char str[4];
} MyUnion;
int main()
{
MyUnion uni = { 0x1A2B3C4D };
//「1A」か「4D」かは環境次第
//「2B」となる環境もある(ミドルエンディアン)
printf("%X", uni.str[0]);
}
他のシステムに移植しないプログラムや、バイトオーダーの違いに左右されない処理であればこのような手法も使用可能です。
例えばビットフィールドを使用する場合、共用体のメンバとして定義し、同じサイズの変数をもうひとつメンバとして持っておくと、ビットフィールドの値を簡単にクリアすることができます。
#include <stdio.h>
//ビットフィールドによるフラグ管理共用体
typedef union {
unsigned char c;
struct {
unsigned char b0 : 1;
unsigned char b1 : 1;
unsigned char b2 : 1;
unsigned char b3 : 1;
unsigned char b4 : 1;
unsigned char b5 : 1;
unsigned char b6 : 1;
unsigned char b7 : 1;
};
} Bitfield;
int main()
{
Bitfield bf = { 0 };
//何らかのフラグ処理
bf.b0 = 0;
bf.b1 = 1;
bf.b2 = 0;
bf.b3 = 1;
//メンバcに0を代入することで
//ビットフィールドをすべてクリアできる
bf.c = 0;
//255(UCHAR_MAX)を代入すれば
//すべて1にセットできる
bf.c = 255;
}
他に、外部とのデータ通信ではデータを1バイト単位にバラして送受信する必要があり、このような場合にも共用体が活用できます。