文字列リソース
文字列をソースファイル外で管理する
通常、プログラムから使用する文字列はソースコード上に直接記述したり外部ファイルから読み込んだりしますが、リソースファイル(リソーススクリプト)に文字列を記述することもできます。
文字列リソースの追加の方法はビットマップファイルの場合と基本的に同じです。
ソリュージョンエクスプローラーから「リソース ファイル」を右クリック→「追加」→「リソース」を選択し、表示されたダイアログから「String Table」を選択し新規作成します。
すると以下のような文字列テーブルエディタが開きます。
(これの正式名称はわかりませんが、ここでは「文字列テーブルエディタ」と呼びます)
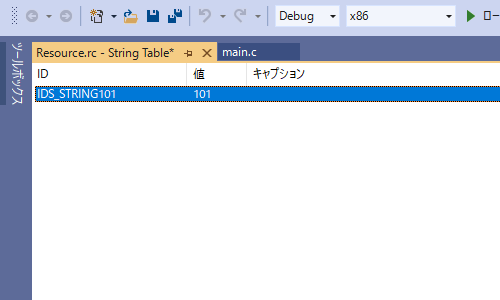
「ID」は文字列の識別子、「値」は管理に使用する整数値(defineされる値)です。
これらはVisual Studioが自動的に割り振ってくれますが、変更することもできます。
「キャプション」の項目にリソースに定義したい文字列を入力します。
例えばアプリケーションのタイトルとメインウィンドウのウィンドウクラス名をリソースファイルに記述すると以下のようになります。
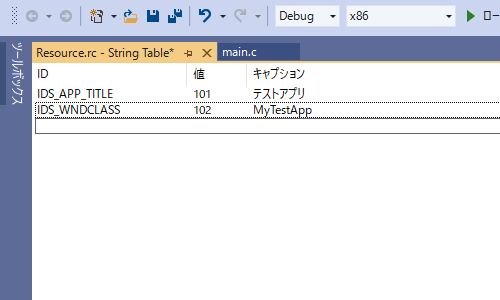
この状態で保存すれば(「CTRL + S」またはメニューから保存)、文字列がリソースに追加されます。
エディタを閉じて、ソリュージョンエクスプローラーからリソーススクリプトファイル(○○.rc)を右クリック→「コードの表示」を選択し、リソーススクリプトエディタを開いてみます。
するとソースの下のほうに以下のような行が追加されています。
/////////////////////////////////////////////////////////////////////////////
//
// String Table
//
STRINGTABLE
BEGIN
IDS_APP_TITLE "テストアプリ"
IDS_WNDCLASS "MyTestApp"
END
リソーススクリプトでの文字列の定義はSTRINGTABLEリソースで行います。
STRINGTABLE [optional-statements]
{
stringID string
...
}
//または
STRINGTABLE
[optional-statements]
BEGIN
stringID string
. . .
END
Vislau Studioは二番目の形式でソースを生成しますが、どちらの形式でも構いません。
「optional-statements」の箇所には言語やバージョン、ユーザー定義情報を記述することができますが、重要ではないので説明は省きます。
(この項目は省略可能です)
ヘッダーファイル(resource.h)を開くと識別子がdefineされています。
//{{NO_DEPENDENCIES}}
// Microsoft Visual C++ で生成されたインクルード ファイル。
// Project1.rc で使用
//
#define IDS_APP_TITLE 101
#define IDS_WNDCLASS 102
// Next default values for new objects
//
#ifdef APSTUDIO_INVOKED
#ifndef APSTUDIO_READONLY_SYMBOLS
#define _APS_NEXT_RESOURCE_VALUE 103
#define _APS_NEXT_COMMAND_VALUE 40001
#define _APS_NEXT_CONTROL_VALUE 1001
#define _APS_NEXT_SYMED_VALUE 101
#endif
#endif
このヘッダーファイルをソースコードにインクルードすることで、識別子から文字列を読み込むことが出来るようになります。
ヘッダーファイル内の「APSTUDIO_INVOKED」セクションは、Visual Studioが識別子に割り振る番号を管理するためのものです。
例えばリソースの場合、次に追加するリソースの番号は「_APS_NEXT_RESOURCE_VALUE」の値が使用されます。
リソースを追加するとこの番号がひとつ増えます。
この番号はリソースの削除などで欠番が発生します。
動作には影響しないので気にする必要はありませんが、気になる人は手動で編集してもかまいません。
LoadString関数
リソースファイルから文字列を読み込むにはLoadString関数を使用します。
- int LoadStringW(
HINSTANCE hInstance,
UINT uID,
LPWSTR lpBuffer,
int cchBufferMax
); - インスタンスhInstanceから識別子uIDで識別される文字列を読み取り、バッファlpBufferにcchBufferMax文字数分(NULL文字含む)格納する。
戻り値はcchBufferMaxが0の場合は取得する文字列の文字数。
cchBufferMaxが0以外の場合は読み取った文字数。
(いずれもNULL文字は含まない)
文字列リソースが存在しない場合は0。
hInstanceは文字列リソースが含まれるインスタンスハンドルです。
通常は実行ファイルのインスタンスハンドルを指定します。
uIDは文字列リソースの識別子です。
lpBufferは読み取った文字列ウを格納する文字列バッファです。
cchBufferMaxは文字列バッファのサイズ(文字数)です。
読み取った文字列の長さがここで指定した文字数を超える場合、文字列を切り捨てバッファはNULL文字で終端します。
戻り値は読み取った文字数です。
例えば以下のように使用します。
「hInstance」は実行ファイルのインスタンスハンドルです。
WCHAR szTitle[128];
LoadString(hInstance, IDS_APP_TITLE, szTitle, 128);
文字数が不明な文字列リソースの読み取り
LoadString関数は第四引数に「0」を指定すると、文字列を読み取らずに文字列リソースの文字数を返します。
(NULL文字は含まれない)
この時、本来は文字列を格納するための第三引数のバッファには文字列リソースへのポインタが格納されます。
第三引数には文字型のポインタ(char*型、WCHAR*型など)の変数を指定します。
これを利用して、文字数が不明な文字列リソースに適切なサイズのバッファを用意することができます。
size_t len;
WCHAR* buf = NULL;
len = LoadString(hInstance, IDS_APP_TITLE, &buf, 0);
buf = malloc(++len * sizeof(WCHAR));
LoadString(hInstance, IDS_APP_TITLE, buf, len);
free(buf);
//エラーチェックは省略しているので注意
文字列リソースへのポインタ(第三引数)は受け取らないと正常に文字数を取得できないようなので(NULLの指定はダメ)、適当なポインタ変数に受け取っておきます。
次に必要なメモリを確保しますが、先ほど取得した文字数にはNULL文字の分は含まれないので1をプラスしておきます。
ここではC言語のmalloc関数を使用します。
後は先ほどと同じ手順で文字列リソースから文字列を読み取ります。
もう一つの方法として、文字列リソースの終端にNULL文字をあらかじめ付加しておくことでも読み取り可能です。
第三引数には指定の文字列リソースへのポインタが格納されるので、ここから直接文字列を読み取ることができます。
(書き換えは不可)
なお、文字列リソースエディタではNULL文字を入力できないのでリソーススクリプトを直接編集する必要があります。
/////////////////////////////////////////////////////////////////////////////
//
// String Table
//
STRINGTABLE
BEGIN
IDS_APP_TITLE "テストアプリ\0 "
IDS_WNDCLASS "MyTestApp\0 "
END
const WCHAR* buf = NULL;
LoadString(hInstance, IDS_APP_TITLE, &buf, 0);
これで変数bufには「テストアプリ」という文字列へのポインタが格納されます。
後はプログラムから通常の文字列ポインタとして使用できます。
ただし、文字列リソースの末尾にそのままNULL文字(\0)を付加すると、なぜかそのNULL文字は無視され次の文字列リソースとひとつながりの文字列として認識されてしまうようです。
そのため、ここではNULL文字の後ろにスペースを挿入しています。
STRINGTABLE
BEGIN
IDS_A "あいうえお\0" //NG
IDS_b "あいうえお\0 " //OK
END