値型と参照型
データ型の分類
データ型でも説明した通り、C#には様々なデータ型が用意されています。
データ型には組み込み型とユーザー定義型という分類方法もありますが、挙動の違いによる分類方法もあります。
それが値型と参照型です。
値型のデータ型
値型は組み込み型のうち、string型とobject型以外のデータ型が該当します。
(bool型、int型、double型など)
その他、列挙型と構造体型も該当します。
プリミティブ型
値型のうち、bool型やint型、double型などの最も基本的な型をプリミティブ型(基本型)といいます。
(単一の値のみで構成される型)
decimal型は内部的には構造体となっており、プリミティブ型ではありません。
参照型のデータ型
参照型は組み込み型のうち、string型とobject型が該当します。
その他、配列型、クラス型、インターフェイス型、デリゲート型といったデータ型も該当します。
値型と参照型の違い
メモリへの保存方法
変数はメモリ上に実際のデータを保存するわけですが、値型と参照型とではメモリへの保存方法が異なります。
値型は、変数の「入れ物」に直接データを保存するイメージです。
例えばint型変数の使用を宣言した時、メモリ上に4バイトの保存領域が確保されます。
その変数に値を代入すると、確保された領域に実データが保存されます。
値型の値が保存されるメモリ領域をスタック領域といいます。
(※常にスタック領域に保存されるとは限らない。後述)
参照型は、変数の「入れ物」と、もうひとつ「別の保存領域」をメモリ上に確保します。
参照型変数に値を代入すると、実データは「別の保存領域」に保存され、変数の「入れ物」にはその保存領域の位置情報であるアドレスを保存します。
実データへのアクセスは、このアドレスを元にして行います。
この「別の保存領域」をヒープ領域といいます。
アドレス自体はスタック領域に保存されます。
(※常にスタック領域に保存されるとは限らない。後述)
■値型と参照型のメモリ上のイメージ1
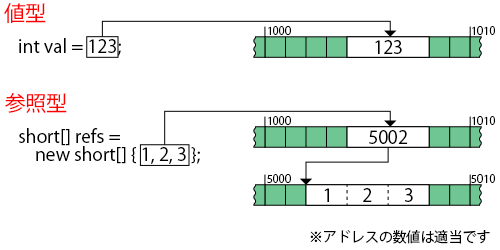
アドレスは自動的に決定され、プログラマが意識することはありません。
値型はイメージしやすいでしょう。
参照型は値へのアクセスの前にワンクッションある、というイメージです。
値型と参照型の違いが現れるのは代入時です。
//値型
int val1 = 123;
int val2 = val1; //val2には[123」が直接入っている
val1 = 456;
Console.WriteLine(val1); //456
Console.WriteLine(val2); //123
//参照型
//ref1には配列そのものが入っているわけではなく
//配列の場所を示すデータ(アドレス)が入っている
short[] ref1 = new short[] { 1, 2, 3 };
//この操作は配列のコピーではなく
//配列のアドレスのコピー
short[] ref2 = ref1;
//ここまでのコードで配列の実体はひとつしか存在しない
//その配列のアドレスはref1とref2が同時に持っている
//配列の要素の書き換え
ref1[0] = 4;
Console.WriteLine(ref1[0]); //4
Console.WriteLine(ref2[0]); //4
456 123 4 4
値型の変数val2に変数val1を代入後、変数val1を書き換えてみます。
これは変数val2の値には何も影響しません。
変数val2の保存領域には変数val1の実データをコピーしたものが保存されるからです。
今度は参照型の変数ref2に変数ref1を代入後、変数ref1の値を書き換えます。
すると変数ref2の値も書き変わってしまいます。
参照型変数ref1に入っているのは実データではなくアドレスです。
ref2 = ref1;で行われるのは「ref2にref1の中身をコピーすること」です。
(これは値型でも同じ動作です)
参照型変数の中身はアドレスですから、つまり参照型変数同士の代入は「アドレスのコピー」であり、実データが保存されている「別の保存領域(ヒープ領域のデータ)」にはノータッチです。
つまり、変数ref1もref2も中身のアドレスが同じになり、同じ「別の保存領域」を読み書きするように指定されることになります。
■値型と参照型のメモリ上のイメージ2
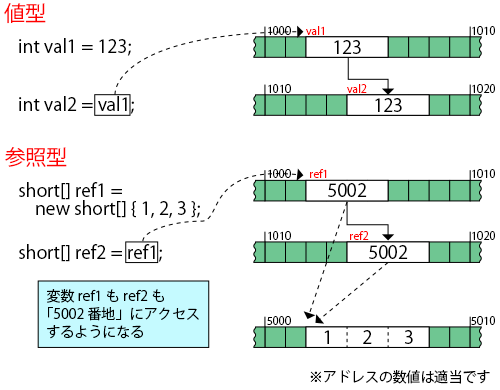
読み書きされる場所が同じなので、一方の変数を通じて値を書き換えるともう一方の変数が読み取る値にも影響がでる、ということです。
配列の丸ごとコピー?で説明したように、配列変数同士の代入でコピーができないのはこれが理由です。
C言語やC++でのポインタとほぼ同じイメージです。
C#の参照型はポインタよりも扱いやすい反面、自由度が低くなったものと言えます。
上記の説明で、値型の実データ、および参照型のアドレス情報は「スタック領域に保存される」と説明しましたが、これは正確ではありません。
正確には、メソッドのローカル変数(メソッドの引数を含む)の値がスタック領域に保存されます。
つまり、値型か参照型かにかかわらず、ローカル変数の「中身」はスタック領域に保存されます。
この「中身」は値型なら実データ、参照型ならばアドレスです。
ローカル変数以外の場合、例えばクラスが持つの変数(フィールド、メンバ変数)は値型であっても「中身」はヒープ領域に保存されます。
参照型のアドレス情報の先にある実データは、(特殊な例外を除いて)常にヒープ領域に保存されます。
参照型のメリット
参照型がわざわざこんな面倒な処理をしているのには理由があります。
最大の特徴は、巨大な値を扱う場合のデータの受け渡しが高速にできることです。
値型の代入では常に実データのコピー処理が発生します。
int型で4バイト、decimal型でも16バイトで、これはそれほど大きなコストではありません。
しかし、例えば参照型であるstring型は長大な文字列が使用可能です。
(最大2GB分らしい)
流石に2GBもの文字列を扱うことはほぼありませんが、int型などに比べれば大きなデータを扱います。
この大きな実データを代入の度にコピーするとメモリをたくさん消費しますし、パフォーマンス的にもよくありません。
そこで、実データは別の場所(ヒープ領域)に保存しておき、変数の「入れ物」(スタック領域)にはデータの場所を示すアドレスを保存します。
代入操作時にはこのアドレスをコピーします。
アドレスのサイズは大きくないので、コピーは高速ですしメモリ使用量も抑えられます。
(サイズは32bitの場合で4バイト、64bitの場合で8バイト)
こうすることでパフォーマンス向上につながります。
代入だけでなく、メソッドに引数としてデータを渡した際にもコピー処理が行われます。
値型を引数に指定した場合は実データをコピーしたものがメソッドに渡されます。
参照型を引数にした場合はアドレスが渡されます。
スタック領域もヒープ領域もメモリ上の領域ですが、スタック領域は「サイズが小さいが高速」という特徴があります。
ひとつのアプリケーションで使用可能なスタック領域のサイズはあまり大きくなく、大容量のメモリを搭載しているPCでも数MB程度です。
(GBではない)
これに対してヒープ領域は「低速だが大容量を扱える」という特徴があります。
32bitアプリケーションでは2GB前後までという制限がありますが、64bitアプリケーションでは実質的に制限なしでシステムのメモリを使用できます。
なお、低速といってもスタック領域と比べた場合の話で、どちらもメモリの読み書きなので十分に高速で、実用上の問題になるほどではありません。
参照型のデメリット
デメリットというほどのものではありませんが、参照型は実データへのアクセスにワンクッションあるので、値型の場合よりも読み書きが若干遅くなります。
また、「参照の参照」といった間接参照が発生する可能性があります。
(参照が示す先が実データではなく、さらに別の参照になっている状態)
これも速度的にはデメリットです。
とはいえ、よほど速度が求められる場面でもなければそこまで気にするほどでもありません。
また、「値型と参照型」という概念を知らないとバグのあるコードを書いてしまう危険性があるのもデメリットと言えるかもしれません。
C言語のポインタなどは変数の宣言時に「これはポインタ変数である」ということがデータ型により明示されますが、C#のデータ型名は値型なのか参照型なのかは見た目ではわかりません。
例えば構造体とクラスは機能的にも似ているため、今使っている型がどちらなのかを意識する必要があります。
object型と値型
object型は参照型ですが、データ型の項でも説明した通り、object型は何でも代入可能な特殊なデータ型です。
int型などの値型も格納可能で、その場合はまるで値型かのように振舞います。
//structは値型
public struct S
{
public int a;
}
//classは参照型
public class C
{
public int a;
}
static void Main(string[] args)
{
S s1 = new S { a = 123 }; //値型
C c1 = new C { a = 123 }; //参照型
object obj1 = s1; //ボックス化
object obj2 = c1;
S s2 = (S)obj1; //ボックス化の解除
C c2 = (C)obj2;
s2.a = 456;
c2.a = 456;
Console.WriteLine("struct(値型) : {0}", ((S)s1).a);
Console.WriteLine("class(参照型): {0}", ((C)c1).a);
}
struct(値型) : 123 class(参照型): 456
struct(構造体型)やclass(クラス型)はまだ説明していませんが、structは値型、classは参照型となるユーザー定義型です。
それぞれをobject型に格納した後、元のデータ型に戻し(s2,c2)、その中身を書き換えています。
その後、最初に宣言した変数(s1,c1)の中身を確認すると、値型のほうは変化していませんが、参照型のほうは値が変化していることが確認できます。
object型は参照型なので、object型変数には常にアドレスが保存されます。
object型変数に値型を格納するとき、実データ(今回は「123」)は「別の保存場所」(ヒープ領域)に保存され、その場所へのアドレスがobject型変数の中身となります。
この動作をボックス化といいます。
ボックス化されているobject型変数の値を使用するには、保存されている値を取り出す必要があります。
これは元のデータ型へのキャストによって行われるのですが、このとき「別の保存場所」からのコピーが行われます。
これをボックス化の解除といいます。
上記のコードの動作を詳細なコメントと共に示します。
//structとclassの定義は省略
static void Main(string[] args)
{
S s1 = new S { a = 123 };
//s1には「123」が直接保存されている
//(スタック領域)
C c1 = new C { a = 123 };
//c1には「123」へのアドレスが保存されている
//アドレスはスタック領域、「123」はヒープ領域にある
//s1の中身をヒープにコピーし、
//そのアドレス情報をobj1に格納する
//(ボックス化)
//この時点でs1とobj1は無関係になる
object obj1 = s1;
//c1の中身(アドレス)をobj2にコピー
//c1とobj2が持っているアドレスは同じ
object obj2 = c1;
//ボックス化の解除
//ヒープからs2(スタック)へ「123」をコピー
S s2 = (S)obj1;
//c2にobj2が持つアドレス情報をコピー
//実データのコピーは起こらない
C c2 = (C)obj2;
//s1のコピーを書き換えているので
//s1には影響しない
s2.a = 456;
//c1とc2が持つアドレス情報は同じなので
//c1の中身を書き換えているのと同じ
c2.a = 456;
}
値型は、ボックス化とボックス化の解除のたびに実データのコピーが発生します。
また、ヒープ領域の確保はスタック領域の確保よりも重い処理なので、全体的にパフォーマンスが良くありません。
そのため、object型に値型を格納することは可能ならば避けた方が良いです。
string型と参照型
string型も参照型ですが、string型変数をメソッドの引数に渡し、メソッド内で書き換えても呼び出し元に影響しません。
static void Main(string[] args)
{
string str = "abc";
FuncStr(str);
Console.WriteLine(str);
Console.ReadLine();
}
//引数を書き換えるメソッド
static void FuncStr(string s)
{
s += "def";
}
abc
「string型は参照型」ということだけを知っていると、上記のコードは今までの説明とは反するような動作に思えるかもしれません。
しかしこれは正常な動作です。
このFuncStrメソッド内の処理は「"文字列abc"が保存されているメモリ領域に"文字列def"を追加する」ではないからです。
正しくは「引数sに保存されているアドレスを、文字列abcとdefを結合して作られた新しい文字列が保存されているメモリ領域のアドレスで上書き」という処理です。
C#では文字列は一度作成した後は不変というルールがあるため、文字列の結合などの単純な操作のたびに新しい文字列が作成されます。
つまり文字列操作の前の、変数strが保存していた文字列(abc)はそのままで、新しい文字列(abcdef)がまた別の領域に作成され、そのアドレスが引数sに格納されます。
■string型を引数に取るメソッドの動作イメージ
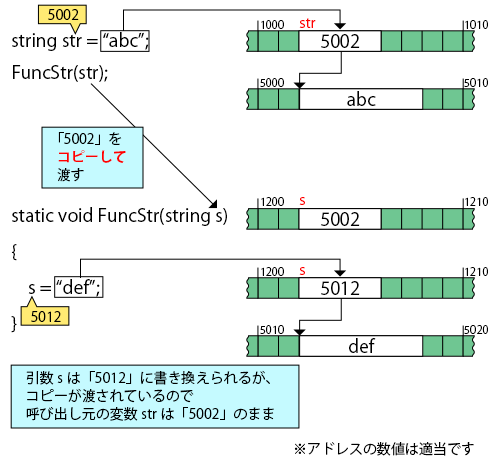
上記コードと同じことをint型配列で行うと動作がよくわかります。
static void Main(string[] args)
{
int[] nums = new int[] { 123 };
FuncArr1(nums);
foreach(var n in nums)
Console.WriteLine(n);
FuncArr2(nums);
foreach (var n in nums)
Console.WriteLine(n);
Console.ReadLine();
}
static void FuncArr1(int[] a)
{
//参照型のアドレスの先の値の書き換え
a[0] = 465;
}
static void FuncArr2(int[] a)
{
//参照型のアドレス自体の書き換え
a = new int[] { 789 };
}
456 456
先ほどのstring型変数の処理は、このコードのFuncArr2と同じことをしています。
メソッド内でいくら引数に格納されているアドレスを書き換えても、呼び出し元には影響しないのです。
ちなみにstring型の要素(文字)は直接書き換えることはできないので、以下のようなコードは書けません。
static void FuncStr(string s)
{
//エラー
//string型の要素は書き換えは不可
s[0] = 'z';
}
string型の実引数をメソッド側で書き換えるには引数の参照渡し(ref、out)を使用します。
参照型とnull
参照型の変数にはnullという値が代入可能です。
これはメモリ上の何処も指していない状態を意味します。
nullが代入されている状態の変数はそのままでは使うことはできません。
int[] nums = null;
//エラー
int count = nums.Length;
上記のコードは、本来ならば配列numsの要素数が取得できますが、配列numsの中身はnullです。
このような場合、要素数0を返すとかそういった動作にはならず、エラー(例外)になります。
配列型やstring型は値がnullになることがあるので、必要に応じて使用する前にnullチェックを行います。
値型でもnull許容値型という特殊なデータ型を使用することでnullを代入可能です。
参照型変数のキャスト
as演算子
データ型の変換はキャスト演算子で行いますが、参照型変数の場合はas演算子を使用して変換することもできます。
//object型は参照型
object objArr = new int[] { 1, 2, 3 };
//配列型は参照型
int[] intArr;
//キャスト演算子
intArr = (int[])objArr;
//as演算子による変換
intArr = objArr as int[];
foreach (var n in intArr)
Console.Write("{0}, ", n);
1, 2, 3,
どちらを使用しても同じ結果を得ることができます。
両者には以下のような違いがあります。
as演算子が使用できるのは参照型だけ
as演算子は値型のデータ型変換には使用できません。
//値型ではas演算子は使用できない
//以下はエラー
int intNum = 5;
short shortNum = intNum as short;
変換に失敗した時の挙動が異なる
as演算子は、目的のデータ型に変換できなかった時の挙動がキャスト演算子と異なります。
キャスト演算子の場合は例外が発生します。
例外の発生は、何も処理をしなければその場でプログラムが停止します。
object objArr = new int[] { 1, 2, 3 };
string str;
//ここでプログラム停止
str = (string)objArr;
例外発生時にプログラムを止めずに処理を続けるには例えば以下のようにします。
とりあえず変換失敗時はstring型変数にnullを代入する処理にしています。
(try~catchはまだ説明していないので参考程度にみてください)
object objArr = new int[] { 1, 2, 3 };
string str;
try
{
str = (string)objArr;
}
catch(Exception e)
{
str = null;
}
as演算子の場合は変換に失敗するとnullが返ります。
object objArr = new int[] { 1, 2, 3 };
string str;
//nullが代入される
str = objArr as string;
if(str == null)
{
//変換失敗
}
else
{
//変換成功
}
変換成功か失敗かはnullと比較すれば良いので、例外発生時のように特殊なコードは必要ありません。
as演算子はユーザー定義のデータ変換はできない
C#では自作クラスのデータ型を別のデータ型に変換する際の変換ルールをユーザーが定義できます。
キャスト演算子は変換ルールを自分で定義できますが、as演算子は定義できません。
これはユーザー定義型への変換にas演算子が使えないという意味ではなく、as演算子の既定の動作を変更する独自の変換ルールを定義することはできないという意味です。
クラスの型変換ルールについてはキャスト演算子のオーバーロードで改めて説明します。
is演算子
as演算子に似ているものにis演算子があります。
これは目的のデータ型への変換ができるか否か(互換性があるか)を判定する演算子です。
object objArr = new int[] { 1, 2, 3 };
string str;
int[] intArr;
//is演算子
if(objArr is string)
str = (string)objArr;
else
str = string.Empty;
//is演算子
if (objArr is int[])
intArr = (int[])objArr;
else
intArr = new int[] { 0 };
Console.WriteLine(str);
foreach (var n in intArr)
Console.Write("{0}, ", n);
1, 2, 3,
is演算子は目的のデータ型に変換可能な場合は真(true)を返すので、if文などを使用して処理を分けることができます。
is演算子で真が返ってきた場合は変換可能なのですから、キャストにはas演算子ではなく通常のキャスト演算子を使用します。
as演算子は内部的に「変換の可否判定 + 変換」の処理のセットとなっているので、is演算子で変換可能と判断された後にas演算子を使用すると、変換の可否判定を二回行うことになり無駄な処理が発生するためです。
パターンマッチング
C#7.0から、is演算子ではパターンマッチングという方法で条件判定が可能になっています。
詳しくは当該ページを参照してください。
参照型のコピー
参照型変数への代入操作は参照情報(アドレス)のコピーで、実データ(参照先のデータ)はコピーされません。
これは参照型のメリットなのですが、時には不都合な場合もあります。
参照型の実データのコピーについてはシャローコピーとディープコピーで改めて説明します。
null条件演算子
参照型に対してはnull条件演算子という演算子が使用できます。
詳しくはnull条件演算子で改めて説明します。