文字コード
文字を表示する仕組み
C言語では文字はchar型で扱います。
char型は文字型ですが内部的には1バイト整数の情報を持ちます。
(signed char型で-128~127、unsigned char型で0~255)
コンピューターで文字を表示する場合、あらかじめ文字毎に番号を割り振っておき、どの文字を表示するかを番号で指定します。
例えば「アルファベットのAは65番」「Bは66番」...と定義しておき、プログラムから「65番目の文字を表示せよ」という指令を出せば「A」が表示される、といった具合です。
char型ひとつでは最大でも256種の文字しか扱えないので、日本語などはchar型ふたつ以上で扱います。
(char型の配列)
どのような文字をサポートし、それぞれの文字に何番を割り振るかを定義したものを文字コードといいます。
文字コードは個々のプログラムで勝手に定義するものではなく、共通の規格です。
サポートする文字の種類を文字集合、番号の割り振り方を符号化方式といいます。
文字コードという言葉はこの両方を含める場合もあれば、文字集合のみ、符号化方式のみを指して文字コードと呼ぶ場合もあります。
(厳密に使い分けられていない場合もあります)
文字コードは結構種類があるのですが、日本語環境で知っておくべきものは「ASCII」「Shift_JIS」「EUC-JP」「UTF-8」「UTF-16」あたりです。
ASCIIは英数字や基本的な半角の記号を扱います。
これだけでは日本語は表現できません。
すべての文字を1バイトで扱います。
改行やタブ文字などの制御文字もこれに含まれています。
C言語で使用する演算子はすべてASCIIの範囲の文字です。
Shift_JISはWindows環境に多く、EUC-JPはUNIX(Linux、Mac)環境に多いです。
どちらも日本語を扱えます。
ASCIIの範囲の文字はASCIIと共通の符号化方式を使用しているため、半角の英数字記号だけを使用する場合はASCIIと互換性があります。
UTF-○○は「Unicode」という文字集合に対する符号化方式です。
Unicodeは扱える文字種が非常に多いのが特徴です。
「UTF-○○」が示す数字は「文字ひとつを最小何ビットで表すか」を表し、例えばUTF-8ならば8ビット(1バイト)が最小のサイズとなります。
あくまでも「最小のサイズ」であり、8ビット固定ではありません。
UTF-8は文字によって1~4バイトを使用します。
(ただしUTF-32は32ビットで固定です)
UTF-8のみ、半角英数字記号はASCIIと互換性があります。
UTF-8は扱える文字種が非常に多く、ASCIIとも一部互換性があり、UTF-16や32よりもデータサイズが抑えられるという特徴があります。
日本語を扱う場合はShift_JISやEUC-JPの方がサイズを抑えられるのですが、今時はデータサイズはそこまで重要視されていないので、WindowsでもLinuxでも広く使用されています。
Windows環境では文字コードに「Unicode」という名称が使われることがありますが、これはUTF-16(LE)のことです。
「Shift_JIS」「EUC-JP」などのつづりはソースコード上では正確に記述すべきです。
使用する関数によっては大文字と小文字の違いやアンダーバーとハイフンの違いなどを受け付けてくれず、意図しない動作となる場合があります。
C言語での文字コード
ソースファイルと実行ファイル
C言語で使用する文字コードは特に取り決めはなく、コンパイラと実行環境(OS)が対応していればどの文字コードでも使用できます。
プログラミング上での文字コードは、まず「ソースファイルの文字コード」があります。
これは単純にソースコードを人が読み書きする時のほか、コンパイラがソースコード上の文字を解釈する時にも関係します。
コンパイラへの「入力」時の文字コードと言えます。
Windows + Visual Studio環境ではShift_JISが標準で使用されます。
Linux + gcc環境ではUTF-8が多いと思います。
(「Linux」は種類が多いので一概には言えませんが)
次に「実行ファイルの文字コード」があります。
これはコンパイラの「出力」時の文字コードで、実行ファイルの内部で使用される文字コードです。
これもWindows + Visual StudioはShift_JIS、Linux + gccはUTF-8が標準です。
Visual Studioやgccは、これらの文字コードを必要に応じて切り替えが可能です。
初期設定のままでも特に問題はありませんが、例えばUTF-8(というかUnicode)にしかない文字をソースコード上に記述したい場合は、Visual Studioの設定を変更してソースファイルをUTF-8にする必要があります。
その他、過去に書いたコードや別の環境から持ってきた(現在の環境とは異なる文字コードの)ソースファイルをコンパイルする場合なども設定を変更することがあります。
Windowsのコンソール(コマンドプロンプト)で使用される文字コードはShift_JISなので、これに無い文字種は基本的に表示できません。
外部との通信やファイルの入出力時にも文字コードを適切に設定する必要があります。
現在の文字コードと異なる文字コードをプログラム上で扱う場合は変換処理が必要になります。
Visual Studioの文字コードをUTF-8にする
上述の通り、Windows + Visual Studioではソースも実行ファイルもShift_JISが使用されます。
そのままでも特に問題はありませんが、他の開発環境に合わせたい場合などもあります。
ここではUTF-8に変更する方法を説明します。
ソースファイルの文字コード
ソースファイルの文字コードを変更するには、「ファイル」メニューから「保存オプションの詳細設定」を選択します。
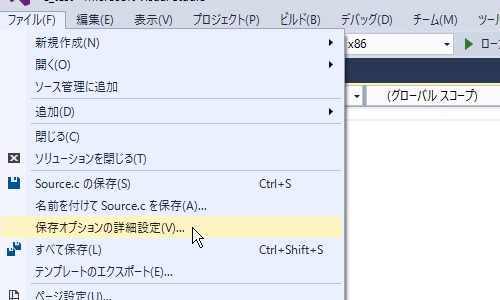
Visual Studio2017では「名前を付けて(ソースコード名)を保存」メニューで開く保存ダイアログに「エンコード付きで保存」というメニューがあるので、これを選択します。
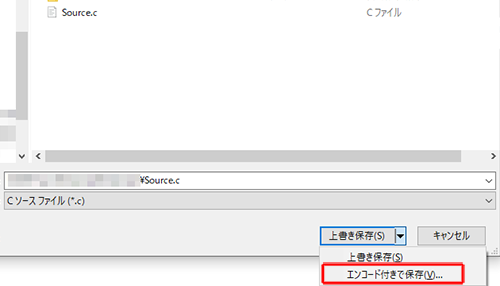
開いたダイアログから「Unicode(UTF-8 シグネチャ付き) - コードページ65001」を選択します。
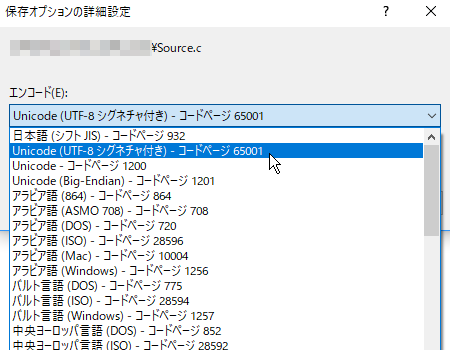
これで現在のソースコードがUTF-8で保存されます。
BOMなしのUTF-8の場合
上記の方法でソースコードを保存すると「UTF-8 BOM付き」という形式で保存されます。
BOMというのは「Byte Order Mark」の略で、テキストファイルの先頭に付加される数バイトのデータのことです。
これには「符号化方式」「ビット表現の方式(ビッグエンディアン、リトルエンディアン)」といった情報が保存されています。
BOM付きのUTF-8の場合はVisual Studioでそのまま読み込むだけでUTF-8として扱ってくれます。
他の環境やテキストエディタなどで作成したソースコードの場合、同じUTF-8でも「BOMなし」で保存されることがあります。
BOMなしのUTF-8はVisual StudioはUTF-8として認識してくれません。
上記手順でVisual Studio上からソースコードをBOMありで保存しなおしたり、Visual Studioで生成したソースコードにコピペで貼り付けたりしても良いですが、数が多いと大変なのでコンパイラオプションで一括してUTF-8と認識させる方法もあります。
コンパイラオプションの変更
実行ファイルの文字コードの変更はコンパイラの設定を変更する必要があります。
上部の「プロジェクト」→「(プロジェクト名)のプロパティ」を開き、左のメニューから「構成プロパティ」→「C/C++」→「コマンドライン」の項目を選択します。
右側下部に「追加のオプション」というテキストエリアがあります。
ここに特定の文字列を追加することで、コンパイラの設定を変更することができます。
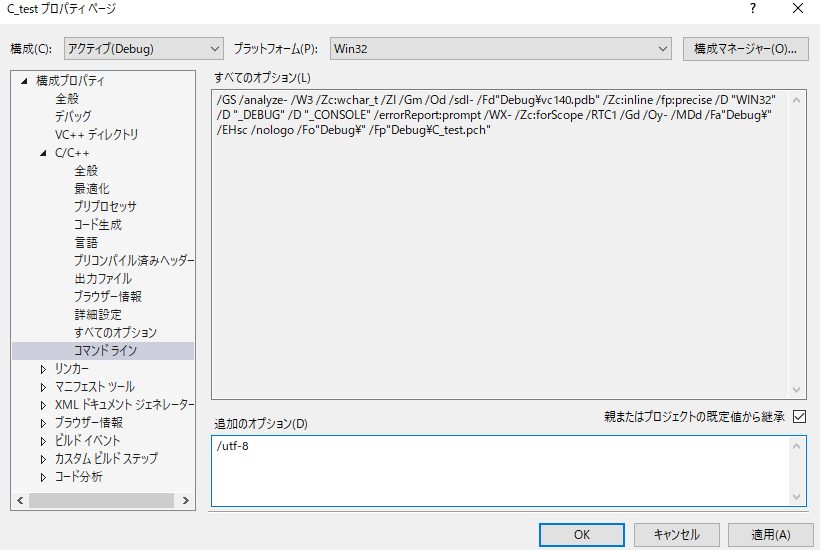
ちなみにその上部に並んでいる「すべてのオプション」の文字列は、設定ダイアログから変更可能なコンパイラオプションです。
ダイアログ内に用意されていないコンパイラオプションを「追加のオプション」欄から追加できます。
ここに「/source-charset:utf-8」を記述すると、ソースファイルをUTF-8として扱います。
あくまでもUTF-8で記述されているとみなすだけで、ソースファイルの文字コードの変換処理をしたりするわけではありません。
ソースファイルの文字コードをコンパイラに知らせるための設定です。
なので、あらかじめファイル自体の文字コードをUTF-8で作っておくか、Visual Studioの文字コードをUTF-8にするの手順でソースファイルの文字コードを変更する必要があります。
Shift_JISのままでもコンパイル可能な場合もありますが、問題が発生する可能性があります。
ソースを「UTF-8 BOMあり」で作成している場合はこのオプションの追加は必要ありません。
(追加しても問題ありません)
「/execution-charset:utf-8」を記述すると、実行ファイルの文字コードがUTF-8となります。
「/utf-8」を記述すると、ソースと実行ファイルの両方にUTF-8を使用するようになります。
つまり「/source-charset:utf-8」「/execution-charset:utf-8」の二つを記述するのと同じです。
(複数のコンパイラオプションを追加する場合は半角スペースを空けて記述します)
ちなみに「/source-charset:shift_jis」「/execution-charset:shift_jis」を記述するとそれぞれにShift_JISを指定することができます。
「/shift_jis」という単独のオプションはありません。
プロパティの変更は、初期状態ではDebugビルドの設定の変更になっています。
Releaseビルドも同じようにコマンドラインに追加してください。
(「すべての構成」で変更しても良いです)
gccの文字コードを変更する
gccの場合も基本的にはVisual Studioの場合と同じで、指定する文字列が異なるだけです。
「-finput-charset=〇〇」「--input-charset=〇〇」でソースファイルの文字コードを設定します。
「-fexec-charset=〇〇」「--exec-charset=〇〇」で実行ファイルの文字コードを設定します。
それぞれ二種類ありますが意味は同じだそうです。
「〇〇」に具体的な文字コードを指定します。
UTF-8はそのままですが、Shift_JISを指定する場合は「CP932」と記述します。
これは「コードページ932」という意味で、Windowsが実装しているShift_JISと思ってください。
例えば以下のように使用します。
$ gcc main.c -o main -finput-charset=CP932 -fexec-charset=UTF-8
これは「main.c」というソースファイルから「main」という名前の実行ファイルを作成し、その際に入力の文字コードにShift_JIS、出力の文字コードにUTF-8を使用する、という意味になります。
gccの場合も、ソースファイルの文字コードをここで設定したからといってソースファイルに文字コードの変換処理がされるわけではないので注意して下さい。
ソースファイル自体をあらかじめ指定の文字コードで作成しておく必要があります。