文字型と文字列
文字型
今までのサンプルコードで使用した変数は、すべて数値を扱うデータ型ばかりでした。
文字を変数に保存しておくこともプログラミングでは頻繁にあります。
文字を変数に保存するにはchar型の変数を使用します。
#include <stdio.h>
int main()
{
char moji = 'A';
printf("変数mojiの中身: %c", moji);
getchar();
}
変数mojiの中身: A
char型は1バイトの情報量を持ち、半角英数字記号を一文字記憶することができます。
printf関数の書式指定文字列で「文字」を表示するには変換指定子%cを使用します。
文字と文字列
char型変数に代入する文字は、ダブルクォーテーションではなくシングルクォーテーション(')で括ることに注意してください。
C言語では、文字と文字列は別物として扱われています。
文字は半角英数字ひとつ、文字列は文字が複数集まったものです。
(半角の記号ひとつも文字です)
日本語などの全角文字は、一文字だけでも文字列として扱われます。
英数字でも全角文字は文字ではなく文字列として扱う必要があります。
そして、文字はシングルクォーテーション、文字列はダブルクォーテーションで括る、というのがルールです。
半角英数文字ひとつだけでも、それをダブルクォーテーションで括ると文字ではなく文字列として扱われます。
反対に、文字列をシングルクォーテーションで括ることはできません。
//ダメ
char moji = "A";
//ダメ
printf('ABC');
厳密には、文字列をシングルクォーテーションで囲んでも文法上はエラーにはなりません。
この場合、文字列を数値として評価しようとします。
printf関数の第一引数に数値は指定できないのでエラーになります。
文字列の扱い方
では、文字列型の変数はというと、実はC言語には「文字列型」というデータ型は存在しません。
しかし文字列を変数に格納することはできます。
それにはchar型の配列を利用します。
#include <stdio.h>
int main()
{
char str[] = "ABCDE";
printf("strの中身: %s", str);
getchar();
}
strの中身: ABCDE
printf関数の変換指定子が%cから%sに変わっている点に注意してください。
文字列を表示するときの変換指定子は「%s」です。
(%cはcharacter(文字)、%sはstring(文字列)の略、と覚えると良いです)
char型配列の宣言時に要素数の指定を省略し、初期化子に文字列を指定すると、自動的にその文字列の長さのchar型配列が作成されます。
後は普通の変数のように、変数の中身を使用することができます。
ただし、このchar型配列には後から別の文字列を代入することはできません。
(これは配列のルールです)
char str[] = "ABCDE";
//これはダメ
str[] = "FGHIJ";
//これもダメ
str = "FGHIJ";
文字列を書き換えるには、配列の各要素にアクセスして書き換えます。
#include <stdio.h>
int main()
{
char str[] = "ABCDE";
str[2] = 'Z';
printf("strの中身: %s", str);
getchar();
}
strの中身: ABZDE
配列の先頭要素は0から始まるので、3番目の文字がZに書き換えられます。
配列中の文字列をすべて置き換えたい場合は、先頭から一文字ずつ書き換えていくか、後のページで説明する文字列操作のための関数を使用します。
NULL文字
char型配列の初期化子に文字列を指定すると、実際の文字数よりも配列のサイズがひとつ大きくなります。
#include <stdio.h>
int main()
{
char str[] = "ABCDE";
int size = sizeof(str);
printf("サイズ: %d", size);
getchar();
}
上記コードのsizeofは、指定したデータ型や変数のサイズ(バイト数)を調べる演算子です。
例えばsizeof演算子にdouble型の変数を指定すると「8」が返ってきます。
- size_t sizeof(type)
- データサイズを返す。
「size_t」という見慣れないデータ型が返ってきますが、これはそのままint型として扱うことができます。
(正確にはint型ではありませんが、まだ説明していないのでただの整数値と思ってください)
char型変数は1バイトの情報量なので、sizeof演算子にchar型配列を指定すると、そのまま配列の要素数が得られます。
さて、上のコードを実行結果は以下になります。
サイズ: 6
「ABCDE」は5文字なのに、それを格納する配列の要素数は6になるのです。
文字列配列を作ると、文字列の最後に自動的にNULL文字という特殊な文字が追加されます。
■メモリ上の文字列の格納イメージ
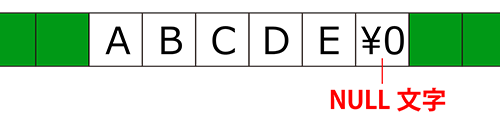
「\0」というのがNULL文字です。
これは文字列の終端を表すために必要な特殊文字です。
C言語では、文字列を読み取るとき、先頭から順に文字を読み込んでいき、NULL文字が登場するとそこを文字列の終わりと判断します。
コード上に文字列(ダブルクォーテーションで括ったもの)を記述すると、自動的に最後にこのNULL文字が付加された状態になります。
なので、「ABCDE」という文字列を格納する配列の要素数は「6」となるわけです。
試しに、文字列配列の途中の文字をNULL文字に替えてみます。
#include <stdio.h>
int main()
{
char str[] = "ABCDE";
str[2] = '\0';
printf("strの中身: %s", str);
getchar();
}
strの中身: AB
文字列が途中で途切れてしまいます。
3文字目をNULL文字を示す\0に変更したので、そこが文字列の終端となるのです。
NULL文字は円記号と数字の0の二文字から成りますが、特殊文字なのでこれで一文字として扱われます。
そのためシングルクォーテーションで括ることに注意してください。
※円記号はバックスラッシュで表示されることがあるので注意してください。
エスケープシーケンス(特殊文字)
文字列中で改行する改行文字は\nという二つの文字を使います。
文字列の終端を表すNULL文字は\0です。
これらはエスケープシーケンス(特殊文字、エスケープ文字)といいます。
円記号に特定の文字を続けると特殊な意味を持つことがあります。
エスケープシーケンスは二文字から成りますが、例外的に一文字として扱われます。
主なエスケープシーケンスには以下があります。
- \a
- 警告音
- \b
- バックスペース
- \n
- 改行(ラインフィード)
- \r
- 改行(キャリッジリターン)
- \t
- タブ文字(水平タブ)
- \v
- タブ文字(垂直タブ)
- \\
- \記号の表示
- \?
- ?記号の表示
- \'
- シングルクォーテーション
- \"
- ダブルクォーテーション
- \0
- NULL文字
円記号が特殊な意味を持つため、円記号自体を表示するには「\\」と記述します。
シングルクォーテーションは、文字列中であればエスケープ文字を使用しなくても表示可能です。
反対に、ダブルクォーテーションを文字として表示する場合はそのまま記述できます。
//エスケープシーケンスが必要
char str[] = "ABC\"DE\"FG"; //「ABC"DE"FG」という文字列
char moji = '\''; //「'」という一文字
//エスケープシーケンスは不要
char str[] = "ABC'DE'FG"; //「ABC'DE'FG」という文字列
char moji = '"'; //「"」という一文字
改行用のエスケープ文字が二つあるのは、環境によって改行コードが異なるからです。
Windowsでは「\r\n」が用いられ、MacOS(UNIX系)では「\n」が用いられます。
(古いMacOSでは「\r」です)
それぞれのシステムで改行コードが異なるので、ファイルをやり取りする際に気を付けないと正しく表示できない事があります。
ただ、通常はC言語のコード中で使用する改行はすべて「\n」で問題ありません。
コンパイラが自動的に最適な改行コードに変換してくれます。
ファイル保存などをするときなどは適切な改行コードを指定する必要があります
コード自体の改行
改行文字ではなく、C言語のコード自体を改行したい場合は以下のようにします。
printf("いろはにほへと ちりぬるを \
わかよたれそ つねならむ");
上記コードは\記号の直後にコードを改行しています。
ダブルクォーテーション中に円記号を書きコードを改行すると、ひとまとまりの文字列と判断されます。
長い文字列は途中で改行するとコードが見やすくなります。
文字列中以外での改行は自由にできます。
C言語では半角スペースやタブ文字、改行文字はすべて同じで、コードの単語同士の区切りの意味しかありません。
全角文字はひとつでも文字列
日本語などの全角文字は一文字であっても文字列として扱う必要があります。
char型は1バイトの情報量ですが、全角文字は2バイト以上の情報量で表されるためです。
//これはダメ
char nihongo1 = 'あ';
//これはOK
char nihongo2[] = "あ";
//英語でも全角なら2バイト以上必要
char zenkaku[] = "A";
なお、全角文字の実際のバイト数は固定ではありません。
char nihongo[] = "あ";
printf("%d", sizeof(nihongo));
3
終端にNULL文字が含まれるため、この場合「あ」一文字のサイズは2バイトということになります。
しかし「"あ"は2バイトである」という決まりはなく、3バイトの環境も存在します。
半角カナ文字は環境による
「アイウエオ」などの半角カナ文字は表示上は半角文字ですが、使用されるバイト数は環境によって異なります。
1バイトの環境もありますが、2バイト以上を前提としてchar型配列で扱うようにしましょう。
「環境」というのは正確に言えば使用している文字コードのことです。
文字コードの話は少しややこしくなるのでここでは省きます。
(文字コードの項で改めて説明します)
半角英数記号以外の文字は2バイト以上を前提としたほうが無難です。
2バイトで固定と考えると移植性の低いコードとなります。
文字と数値
文字というのは内部的には数値で管理されています。
例えばアルファベットの「A」は65番、「B」は66番…といった具合です。
実際にchar型変数を数値として表示してみます。
#include <stdio.h>
int main()
{
char mojiA = 'A';
char mojiB = 'B';
printf("%d\n", mojiA);
printf("%d\n", mojiB);
getchar();
}
65 66
printf関数の変換指定子に%cではなく%dを指定しています。
つまり文字ではなく数値として扱っています。
文字は数値としても扱えるため、int型変数に格納することもできます。
文字を返す関数の中にはint型として返すものもあります。
「文字は数値である」という特性を利用すれば、ある文字が特定の文字間に存在するかを判定することもできます。
#include <stdio.h>
int main()
{
char moji = 'E';
if ('A' <= moji && moji <= 'Z')
printf("「%c」はA~Zの間の文字です", moji);
else
printf("「%c」はA~Zの間の文字ではありません", moji);
getchar();
}
「E」はA~Zの間の文字です
if文はまだ説明していないので参考程度に見てください。
アルファベットはAからZまでが順番に数値が割り振られています。
判定対象の「E」も、「A」も「Z」も内部的には数値なので、上記のようなコードで対象の文字が大文字のアルファベットの範囲か否かを判定できます。
ただしこの手法が使えるのは英数記号の判別だけです。
それ以外の文字(日本語など)の場合は環境(文字コード)によって並び順が異なるので移植性が低くなります。
より厳密に言えばASCIIと互換性のない文字コードの場合、英数字であっても動作は保障されません。
一般的な文字コードでは大丈夫ですが、特殊な文字コードを扱う場合は注意が必要かもしれません。