ワイド文字
一文字のサイズが固定の文字型
マルチバイト文字の項で説明したように、マルチバイト文字は扱いが大変です。
文字種によって必要なバイト数が異なることが煩雑になる最大の原因で、これが固定ならばかなり楽になるはずです。
それを実現するのがワイド文字です。
ワイド文字はchar型の代わりにwchar_t型というデータ型で扱います。
これは<wchar.h>または<stdlib.h>をインクルードすることで使用できるようになります。
単にwchar_t型を使用するだけならどちらか一方で構いませんが、一方にしか定義されていない関数もあるので両方をインクルードしておきます。
実際にwchar_t型を使用してみます。
#include <stdio.h>
//<wchar.h>をインクルード
#include <wchar.h>
int main()
{
wchar_t wmoji1 = L'A';
wchar_t wmoji2 = L'あ';
wchar_t wstr[] = L"ABCあいう";
printf("%d\n", sizeof(wmoji1));
printf("%d\n", sizeof(wmoji2));
printf("%d\n", sizeof(wstr));
getchar();
}
2 2 14
それぞれの文字や文字列の手前にLというプリフィックス(接頭語)が付けられています。
これはその文字、文字列がワイド文字であることを表します。
Lを付けた文字はwchar_t型の変数に、文字列はwchar_t型の配列にそれぞれ格納できます。
英数字でも日本語でも扱いが変わることはありません。
上記コードはそれぞれの変数と配列のサイズを表示しています。
文字はアルファベットも日本語も同じサイズ(2バイト)であることが分かります。
配列内の文字数は6文字ですが、最後のNULL文字も合わせて「7文字 × 2バイト = 14バイト」となっています。
(NULL文字も2バイトとなります)
上記の実行結果では一文字あたり2バイトとなっていますが、wchar_t型のサイズはC言語の仕様では決められておらず、コンパイラによって変わります。
Linuxのgccでは4バイトです。
ワイド文字で使用される文字コードには決まりはありませんが、UTF-16であることが多いそうです。
(Windows Visual Studio、Windows Clang、Linux gccで確認)
ワイド文字を使うべきか
ワイド文字はマルチバイト文字の「文字種によってサイズが変わる」という問題を解決するためのものです。
しかし仕様制定当時に想定しないほど文字種が増加してしまい、現在はwchar_t型ひとつでは表現できない文字が存在しています。
そのような文字はマルチバイト文字と同じように、wchar_t型ふたつで表現することになります。
これではワイド文字を使用するメリットが薄れてしまいます。
マルチバイト文字に比べてその出現頻度は低く、通常ではあまり問題にはならないのですが、完全に2バイト(または4バイト)で決め打ちしてしまうと問題となる可能性があることには注意せねばなりません。
ユーザーからの文字の入力やテキストファイルの読み込みがあるプログラムの場合は、アルファベットでも日本語でも一文字あたりのバイト数が(基本的には)一定なので扱いが容易になる可能性があります。
そうでないのならば従来通りマルチバイト文字を使用しても問題ありません。
char16_t型、char32_t型
ワイド文字にはwchar_t型のほかにchar16_t型とchar32_t型が存在します。
これはC11というC言語の規格で追加されました。
これらは<uchar.h>をインクルードすることで使用できるようになります。
char16_t型は16ビット(2バイト)、char32_t型は32ビット(4バイト)のデータ型です。
char32_t型ならばUTF-32と同じなので、これひとつで今のところすべての文字種を表現可能と思われます。
(ただし使用する文字集合がUnicodeなので、Unicodeで表現できる文字に限る)
char16_t型の文字、文字列にはプリフィックスとしてuを指定します。
char32_t型の文字、文字列にはプリフィックスとしてUを指定します。
#include <stdio.h>
//<uchar.h>をインクルード
#include <uchar.h>
int main()
{
char16_t c16 = u'あ';
char32_t c32 = U'あ';
char16_t str16[] = u"あいうえお";
char32_t str32[] = U"あいうえお";
}
ただ、これらの型をそのまま使用できる関数はほぼ実装されておらず、使い勝手が良いとは言えません。
mbrtoc16、mbrtoc32、c16rtomb、c32rtombなどの関数でマルチバイト文字との相互変換は可能です。
マルチバイト文字/ワイド文字の相互変換
マルチバイト文字とワイド文字は相互に変換することができます。
マルチバイト文字をワイド文字に変換するにはmbtowc関数を使用します。
ワイド文字をマルチバイト文字に変換するにはwctomb関数を使用します。
どちらもstdlib.hのインクルードが必要です。
#define _CRT_STDIO_ISO_WIDE_SPECIFIERS
#include <stdio.h>
#include <stdlib.h>
#include <wchar.h>
#include <locale.h>
#include <limits.h>
int main()
{
char mc1[] = "あ";
wchar_t wc1 = L'あ';
//全てのロケールでの一文字の最大バイト数 + 1を確保
//最後の+1はNULL文字用
char mc2[MB_LEN_MAX + 1];
wchar_t wc2;
//システム既定のロケールに設定
setlocale(LC_ALL, "");
//マルチバイト文字をワイド文字に変換
int len = mbtowc(&wc2, mc1, MB_CUR_MAX);
if (len < 0)
{
wprintf(L"マルチバイト文字からワイド文字への変換失敗\n");
}
else
{
wprintf(L"%lc\n", wc2);
}
//ワイド文字をマルチバイト文字に変換
len = wctomb(mc2, wc1);
if (len < 0)
{
wprintf(L"ワイド文字からマルチバイト文字への変換失敗\n");
}
else
{
//文字の最後にNULL文字を追加
mc2[len] = '\0';
wprintf(L"%s\n", mc1);
}
getchar();
}
あ あ
文字処理関数はロケールの影響を受けるため、まずsetlocale関数でシステム既定のロケールに設定します。
ワイド文字の変換先となるchar型配列mc2のサイズはMB_LEN_MAXという定数を利用して指定しています。
(<limits.h>のインクルードが必要)
これはすべてのロケール(環境)で使用されるマルチバイト文字中、一文字あたりの最大バイト数が格納されています。
これを指定すれば変換後のデータを格納する配列のサイズが足りない、ということはありません。
最後にNULL文字も入るので+1した値を指定しています。
mbtowc関数は第一引数に変換先となるwchar_t型変数のアドレスを指定します。
(詳しくはポインタを参照)
第二引数は変換元となるマルチバイト文字を指定します。
第三引数にはマルチバイト文字の一文字あたりの最大バイト数を指定します。
ここではマルチバイト文字の文字数の取得の項でも使用したMB_CUR_MAXを指定しています。
変換に成功した場合はマルチバイト文字のバイト数を返します。
失敗した場合は-1を返します。
wctomb関数は第一引数に変換先となるchar型配列を指定します。
配列名をそのまま記述すればアドレスを渡すことになるのでアドレス演算子(&)は不要です。
第二引数には変換元となるワイド文字を指定します。
変換に成功した場合はマルチバイト文字のバイト数を返します。
失敗した場合は-1を返します。
この戻り値を利用して、文字列の末尾にNULL文字を挿入します。
MB_LEN_MAXは全てのロケール上での、マルチバイト文字が使用し得る最大のバイト数を示すマクロ定数です。
MB_CUR_MAXは現在のロケール上でのマルチバイト文字の最大のバイト数ですが、これは定数とは限りません。
つまり配列の要素数の指定にMB_CUR_MAXを指定することはできません。
上記のサンプルコードでは、配列の要素数にMB_LEN_MAX + 1を指定している箇所がありますが、実際に必要なサイズはMB_CUR_MAX + 1です。
サイズがMB_LEN_MAX > MB_CUR_MAXの場合は無駄なメモリ領域が発生していることになります。
これは上記の通り配列のサイズの指定にMB_CUR_MAXを指定できないので、サンプルコードの簡略化のための措置です。
実際のプログラムではmalloc関数などでメモリを動的確保した方が良いでしょう。
wprintf関数
文字列の表示に使用しているwprintf関数は、標準入出力にワイド文字を表示する関数です。
ワイド文字に対応している以外はprintf関数と同等です。
ただし使用の前にsetlocale関数の実行が必要です。
書式指定文字列自体もワイド文字を使用する必要があるので、文字列の先頭に「L」を付加します。
ワイド文字を出力する場合は変換指定子に%lc、文字列の場合は%lsを指定します。
マルチバイト文字を出力する場合は通常通り%c、%sを指定します。
#define _CRT_STDIO_ISO_WIDE_SPECIFIERS
//↑Visual Studio用
#include <stdio.h>
#include <wchar.h>
#include <locale.h>
int main()
{
setlocale(LC_ALL, "");
//setlocale(LC_ALL, "ja_JP.utf8");
wchar_t str1[] = L"あいうえお";
char str2[] = "かきくけこ";
wprintf(L"%ls\n", str1);
wprintf(L"%s\n", str2);
}
あいうえお かきくけこ
Visual Studioの場合、printf関数とwprintf関数の変換指定子に独自仕様があるので注意が必要です。
printf関数で文字の出力に%C、文字列の出力に%Sを指定するとwchar_t型が要求されます。
wprintf関数で%C、%Sを指定するとchar型が要求されます。
ここまでは良いのですが、wprintf関数で%c、%sを指定すると、C言語の規格ではchar型が要求されますが、Visual Studioではwchar_t型が要求されます。
これは後述するTCHAR型への対応のための拡張と思われますが、移植性の面ではよくありません。
コードの先頭に#define _CRT_STDIO_ISO_WIDE_SPECIFIERSを指定すると、C言語本来の意味と同等になります。
printf関数とwprintf関数を混在させると表示がおかしくなる可能性があります。
実際に使用するコードではどちらか一方のみを使用することを推奨します。
wctomb_s関数
wctomb関数にはセキュア版であるwctomb_s関数が存在します。
可能ならばこちらの使用が推奨されます。
#define _CRT_STDIO_ISO_WIDE_SPECIFIERS
#include <stdio.h>
#include <stdlib.h>
#include <wchar.h>
#include <locale.h>
#include <limits.h>
int main()
{
wchar_t wc = L'あ';
char mc[MB_LEN_MAX + 1];
int len;
setlocale(LC_ALL, "");
//ワイド文字をマルチバイト文字に変換
//セキュア版
errno_t err = wctomb_s(&len, mc, sizeof(mc), wc);
if (err != 0)
{
printf("ワイド文字からマルチバイト文字への変換失敗\n");
}
else
{
mc[len] = '\0';
printf("%s\n", mc);
}
getchar();
}
あ
第一引数は変換後のマルチバイト文字のバイト数を格納するint型変数のアドレスを指定します。
第二引数は変換先のマルチバイト文字を指定します。
第三引数は書き込む最大サイズです。
第四引数は変換元のワイド文字を指定します。
戻り値はerrno_t型です。
変換に成功すれば0が、失敗なら0以外(定数EINVAL)が返ってきます。
マルチバイト文字列/ワイド文字列の相互変換
「文字」ではなく「文字列」をダイレクトに変換することもできます。
マルチバイト文字列をワイド文字列に変換するにはmbstowcs関数を使用します。
ワイド文字列をマルチバイト文字列に変換するにはwcstombs関数を使用します。
どちらも<stdlib.h>のインクルードが必要です。
#define _CRT_STDIO_ISO_WIDE_SPECIFIERS
#include <stdio.h>
#include <stdlib.h>
#include <wchar.h>
#include <locale.h>
#include <limits.h>
int main()
{
char ms1[] = "あいうえお";
wchar_t ws1[] = L"あいうえお";
//ワイド文字の文字数 × 一文字あたりのバイト数
char ms2[sizeof(ws1) / sizeof(ws1[0]) * MB_LEN_MAX];
//単純な文字数分の容量で良いが
//マルチバイト文字の文字数を正確に計算することは容易ではないので
//大き目の容量を確保しておく
wchar_t ws2[16];
//システム既定のロケールに設定
setlocale(LC_ALL, "");
//マルチバイト文字列をワイド文字列に変換
int len = mbstowcs(ws2, ms1, sizeof(ws1) / sizeof(ws1[0]));
if (len < 0)
{
wprintf(L"マルチバイト文字列からワイド文字列への変換失敗\n");
}
else
{
wprintf(L"%ls\n", ws2);
}
//ワイド文字列をマルチバイト文字列に変換
len = wcstombs(ms2, ws1, sizeof(ms1));
if (len < 0)
{
wprintf(L"ワイド文字列からマルチバイト文字列への変換失敗\n");
}
else
{
wprintf(L"%s\n", ms2);
}
getchar();
}
あいうえお あいうえお
ワイド文字列→マルチバイト文字列の変換には「ワイド文字列の文字数 × 一文字あたりのバイト数」のサイズのchar型配列が必要です。
ワイド文字列の文字数をsizeof演算子を利用して計算し、MB_LEN_MAXを掛けることで必要なバイト数が得られます。
(前述の通り、正確にはMB_CUR_MAXを使用した方が良いです)
マルチバイト文字列→ワイド文字列の場合はマルチバイト文字列の文字数分のサイズのwchar_t型配列があれば良いのですが、これを計算するのは簡単ではないのでここでは適当な大きさのサイズを確保しています。
マルチバイト文字列の文字数を得るにはマルチバイト文字の文字数の取得の項を参考にしてください。
mbstowcs関数の第一引数には変換先のwchar_t型配列を指定します。
第二引数は変換元となるマルチバイト文字列を指定します。
第三引数はchar_t型配列のサイズを指定します。
戻り値は変換された文字数です。
失敗した場合は-1を返します。
wcstombs関数の第一引数には変換先のchar型配列を指定します。
第二引数には変換元となるワイド文字列を指定します。
第三引数にはchar型配列のサイズを指定します。
戻り値は変換されたバイト数です。
失敗した場合は-1を返します。
mbstowcs_s関数、wcstombs_s関数
mbstowcs関数、wcstombs関数にはそれぞれセキュア版であるmbstowcs_s関数、wcstombs_s関数が存在します。
可能ならばこちらの使用が推奨されます。
#define _CRT_STDIO_ISO_WIDE_SPECIFIERS
#include <stdio.h>
#include <stdlib.h>
#include <wchar.h>
#include <locale.h>
#include <limits.h>
int main()
{
char ms1[] = "あいうえお";
wchar_t ws1[] = L"あいうえお";
char ms2[sizeof(ws1) / sizeof(ws1[0]) * MB_LEN_MAX];
wchar_t ws2[128];
size_t len;
setlocale(LC_ALL, "");
//マルチバイト文字列をワイド文字に変換
//セキュア版
errno_t err = mbstowcs_s(&len, ws2, sizeof(ws2), ms1, _TRUNCATE);
if (err != 0)
{
wprintf(L"マルチバイト文字列からワイド文字列への変換失敗\n");
}
else
{
wprintf(L"%ls\n", ws2);
}
//ワイド文字列をマルチバイト文字に変換
//セキュア版
err = wcstombs_s(&len, ms2, sizeof(ms2), ws1, _TRUNCATE);
if (err != 0)
{
wprintf(L"ワイド文字列からマルチバイト文字列への変換失敗\n");
}
else
{
wprintf(L"%s\n", ms2);
}
getchar();
}
あいうえお あいうえお
mbstowcs_s関数の第一引数には変換後のワイド文字列の文字数を格納するsize_t型変数のアドレスを指定します。
(size_t型は符号なし整数型)
第二引数には変換先のワイド文字列を指定します。
第三引数には変換先のワイド文字列の文字数を指定します。
第四引数には変換元のマルチバイト文字列を指定します。
第五引数には変換する最大の文字数(NULL文字は省く)を指定します。
_TRUNCATEを指定すると自動的に変換先のワイド文字列のサイズに設定されます。
wcstombs_s関数の第一引数には変換後のマルチバイト文字のバイト数を格納するint型変数のアドレスを指定します。
第二引数には変換先のマルチバイト文字列を指定します。
第三引数には変換先のマルチバイト文字列の文字数を指定します。
第四引数には変換元のワイド文字列を指定します。
第五引数には変換する最大の文字数(NULL文字は省く)を指定します。
_TRUNCATEを指定すると自動的に変換先のマルチバイト文字列のサイズに設定されます。
どちらも戻り値はerrno_t型で、成功した場合は0を返します。
失敗した場合は0以外を返します。
マルチバイト文字、ワイド文字対応の関数
C言語標準の文字列操作関数は基本的に1バイト文字を想定しており、そのままではマルチバイト文字やワイド文字で使用できないものがあります。
文字数を数えるstrlen関数などがその典型です。
こういった関数にはマルチバイト用、ワイド文字用が別に用意されている場合があります。
文字列操作関数の名前には「str」という文字が付けられています。
これは文字列を意味する「string」の略称です。
これらの関数は一文字が1バイトである文字列の使用を前提としています。
マルチバイト文字用の関数には「mb」や「mbs」が付けられます。
(Multi Byte String)
ただ、「mbs」系の関数はほぼMicrosoftの独自拡張で、VisualStudioでしか使用できません。
ワイド文字用の関数には「w」や「wc」、「wcs」が付けられます。
(Wide Character String。characterは「文字」の意味)
具体的な関数名はページ下部のそれぞれの文字型の関数名の対応に示します。
TCHAR型
Visual StudioにはTCHAR型という文字型が存在します。
これはマルチバイト文字とワイド文字の両方に対応するための型です。
TCHAR型は<tchar.h>をインクルードすると使用できます。
TCHAR型は特別なものではなく、「char型」または「wchar_t型」の別名(typedefしたもの)です。
どちらになるかはコンパイル時の設定で決められますが、その設定はVisual Studio上から行います。
Visual Studioのプロジェクトの設定を開くと(「プロジェクト」メニュ→「(プロジェクト名)のプロパティ」)、「全般」メニュー内に「文字セット」という項目があります。
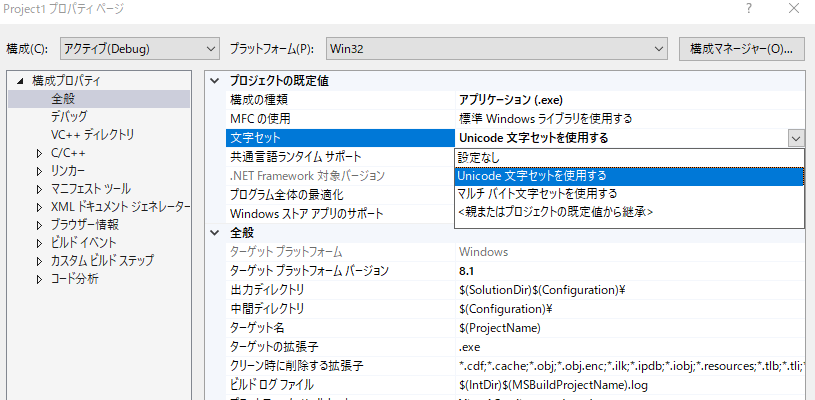
Visual Studio2019では「全般」ではなく「詳細」メニュー内に移動しています。

この設定が「Unicode文字セットを使用する」になっている場合、TCHAR型はwchar_t型の別名となります。
「マルチバイト文字セットを使用する」になっている場合はTCHAR型はchar型の別名となります。
この設定はTCHAR型の実際の型を決定するだけです。
「Unicode文字セットを使用する」に設定したからといってプログラムでUTF-8やUTF-16のテキストファイルが読み書きできるようになるわけではありません。
TCHAR型はUnicode対応の環境用のプログラムと非対応の環境用のプログラムを、ひとつのソースコードでコンパイルできるようにするための仕組みです。
ただ、今はUnicode非対応の環境というのがほとんどないのでwchar_t型をそのまま使用してもほぼ問題ありません。
むしろTCHAR型は完全にマイクロソフト仕様なので移植性がなく、あまり使用すべきではないかもしれません。
_Tマクロ、_TEXTマクロ
ワイド文字の文字(列)リテラルは、ワイド文字であることを示す「L」プリフィックスが必要です。
TCHAR型を使用する場合、設定によってchar型とwchar_t型が切り替わるので、文字リテラルもこの設定に連動して切り替える必要があります。
それには_Tマクロ、_TEXTマクロを使用します。
TCHAR tc1 = _T('あ');
TCHAR tc2 = _TEXT('い');
TCHAR tstr1[] = _T("あいうえお");
TCHAR tstr2[] = _TEXT("かきくけこ");
このように記述すると、VisualStudioの上記の文字セットの設定が「Unicode文字セットを使用する」になっている場合、自動的に「L」プリフィックスを付けた文字(列)に置き換えられます。
「マルチバイト文字セットを使用する」の場合は何もプリフィックスを付けない通常の文字(列)となります。
これはマクロなので、コンパイル時に置き換えられます。
_Tマクロと_TEXTマクロに違いはありません。
記述が短い_Tマクロで良いでしょう。
TCHAR型の文字列操作関数
TCHAR型は設定でデータ型が切り替わるので、そのままではマルチバイト文字用、ワイド文字用のどちらの関数も使用することはできません。
そのため、専用の(TCHAR型を引数に取る)関数が必要となります。
TCHAR型に対応した関数は、頭に「_t」「tcs」などが付いています。
(ただし_ftprintfなど変則的なものもあります)
この関数はVisualStudioの設定によって自動的にマルチバイト用/ワイド文字用の関数に呼び出しを切り替えてくれます。
#include <stdio.h>
#include <locale.h>
#include <tchar.h>
int main()
{
setlocale(LC_ALL, "");
TCHAR str1[] = _T("あいうえお");
TCHAR str2[sizeof(str1) / sizeof(TCHAR)];
//TCHAR型がchar型ならばstrcpy_s関数が、
//wchar_型ならばwcscpy_s関数が呼び出される
_tcscpy_s(str2, sizeof(str2) / sizeof(TCHAR), str1);
//TCHAR型がchar型ならばprintf関数が、
//wchar_型ならばwprintf関数が呼び出される
_tprintf(_T("%s"), str2);
getchar();
}
あいうえお
それぞれの文字型の関数名の対応
以下にシングルバイト文字用、マルチバイト文字用、ワイド文字用、TCHAR用のそれぞれの関数の名称を示します。
マルチバイト文字は基本的にシングルバイト文字用と共用ですが、関数によっては正しい結果が得られない場合があります。
(文字数を数えるstrlen関数など)
関数名がアンダースコア(_)から始まるものはVisualStudioでのみ使用できます。
末尾が「_s」系の関数(セキュア版)はコンパイラによっては使用できない場合があります。
VisualStudioの既定の設定では、セキュア版がある関数は非セキュア版の使用が禁止されているものがあります。
使用できるようにするには_s系関数とエラー表示についてを参照してください。
| 概要 | 1バイト文字 | マルチバイト文字 | ワイド文字 | TCHAR型 |
|---|---|---|---|---|
| 標準出力に文字列を出力 | printf printf_s |
printf printf_s |
wprintf wprintf_s |
_tprintf _tprintf_s |
| ファイルに文字列を出力 | fprintf fprintf_s |
fprintf fprintf_s |
fwprintf fwprintf_s |
_ftprintf _ftprintf_s |
| 文字列を整形 | sprintf sprintf_s |
sprintf sprintf_s |
swprintf swprintf_s |
_stprintf _stprintf_s |
| サイズを指定して文字列を整形 | snprintf _snprintf_s |
snprintf _snprintf_s |
_snwprintf _snwprintf_s |
_sntprintf _sntprintf_s |
| 引数リストを使用したprintf | printf系関数の先頭にvを付加 (アンダースコアから始まるものを除く) 例: vprintf、vfwprintf |
|||
| 標準入力からデータを取得 | scanf scanf_s |
scanf scanf_s |
wscanf wscanf_s |
_tscanf _tscanf_s |
| ファイルからデータを取得 | fscanf fscanf_s |
fscanf fscanf_s |
fwscanf fwscanf_s |
_ftscanf _ftscanf_s |
| 文字列からデータを取得 | sscanf sscanf_s |
sscanf sscanf_s |
swscanf swscanf_s |
_stscanf _stscanf_s |
| 引数リストを使用したscanf | scanf系関数の先頭にvを付加 (アンダースコアから始まるものを除く) 例: vscanf、vfwscanf |
|||
| 概要 | 1バイト文字 | マルチバイト文字 | ワイド文字 | TCHAR型 |
|---|---|---|---|---|
| 文字列の長さを取得 | strlen strlen |
strlen _mbslen |
wcslen wcslen |
_tcslen _tcsclen |
| サイズを指定して文字列の長さを取得 | strnlen strnlen strnlen_s |
strnlen _mbsnlen strnlen_s |
wcsnlen wcsnlen wcsnlen_s |
_tcsnlen _tcscnlen |
| 文字列をコピー | strcpy strcpy_s |
_mbscpy _mbscpy_s |
wcscpy wcscpy_s |
_tcscpy _tcscpy_s |
| サイズを指定して文字列をコピー | strncpy strncpy_s |
_mbsnbcpy _mbsnbcpy_s _mbsncpy _mbsncpy_s |
wcsncpy wcsncpy_s |
_tcsncpy _tcsncpy_s |
| 文字列を結合 | strcat strcat_s |
_mbscat _mbscat_s |
wcscat wcscat_s |
_tcscat _tcscat_s |
| サイズを指定して文字列を結合 | strncat strncat_s |
_mbsncat _mbsncat_s |
wcsncat wcsncat_s |
_tcsncat _tcsncat_s |
| 文字列を比較 | strcmp | _mbscmp | wcscmp | _tcscmp |
| サイズを指定して文字列を比較 | strncmp strncmp |
_mbsncmp _mbsnbcmp |
wcsncmp wcsncmp |
_tcsnccmp _tcsncmp |
| 文字列から指定文字が出現する位置を取得 | strchr | _mbschr | wcschr | _tcschr |
| 後ろから検索して文字列から指定文字が出現する位置を取得 | strrchr | _mbsrchr | wcsrchr | _tcsrchr |
| 文字列から指定文字列が出現する位置を取得 | strstr | _mbsstr | wcsstr | _tcsstr |
| 文字列から指定文字列が出現するまでの長さを取得 | strcspn | _mbscspn | wcscspn | _tcscspn |
| 文字列を指定文字で分割 | strtok | _mbstok | wcstok | _tcstok |
| 概要 | 1バイト文字 | マルチバイト文字 | ワイド文字 | TCHAR型 |
|---|---|---|---|---|
| ファイルを開く | fopen fopen_s |
fopen fopen_s |
_wfopen _wfopen_s |
_tfopen _tfopen_s |
| ファイルから文字を取得 | fgetc | fgetc | fgetwc | _fgettc |
| ファイルから文字列を取得 | fgets | fgets | fgetws | _fgetts |
| ファイルに文字を出力 | fputc | fputc | fputwc | _fputtc |
| ファイルに文字列を出力 | fputs | fputs | fputws | _fputts |
| 標準入力から文字を取得 | getc | getc | getwc | _gettc |
| 標準入力から文字列を取得 ※getsは非推奨関数 |
gets gets_s |
gets gets_s |
_getws _getws_s |
_getts _getts_s |
| 標準入力に文字を出力 | putc | putc | putwc | _puttc |
| 標準入力に文字列を出力 | puts | puts | _putws | _putts |
_wfopen関数は引数の指定にワイド文字を使用するようになるだけで、読み書きされるデータの内容が変わるわけではありません。