ランダムアクセス
ファイル処理6
ランダムアクセスとは
今までのファイル処理は、先頭から順に読み書きするものでした。
このようなアクセス方法をシーケンシャルアクセスといいます。
ファイル上のデータは常に先頭から処理を行うわけではなく、「○バイト目のデータにアクセスしたい」という場合もあります。
ファイル内の任意の位置への読み書きする方法をランダムアクセスといいます。
ファイル位置(ファイル位置指示子)を移動させるにはfseek関数を使用します。
#include <stdio.h>
void Write(const char *file)
{
FILE *fp;
//fp = fopen(file, "wb");
fopen_s(&fp, file, "wb");
if (fp == NULL)
{
printf("%sのオープンに失敗しました。\n", file);
return;
}
//ファイルに書き込むデータ
int intArr[] = { 1, 2, 3, 4, 5,
6, 7, 8, 9, 10 };
//ファイル書き込み
fwrite(intArr, sizeof(int), 10, fp);
fclose(fp);
printf("%sに保存しました。\n", file);
}
void Read(const char *file)
{
FILE *fp;
//fp = fopen(file, "rb");
fopen_s(&fp, file, "rb");
if (fp == NULL)
{
printf("%sのオープンに失敗しました。\n", file);
return;
}
int integer;
//ファイル位置を指定する変数
size_t pos;
pos = sizeof(int) * 2;
fseek(fp, pos, SEEK_SET);
fread(&integer, sizeof(int), 1, fp);
printf("先頭から%dバイト目のデータ: %d\n", pos, integer);
pos = sizeof(int) * 0;
fseek(fp, pos, SEEK_CUR);
fread(&integer, sizeof(int), 1, fp);
printf("前回から%dバイト後のデータ: %d\n", pos, integer);
pos = sizeof(int) * 3;
fseek(fp, pos, SEEK_CUR);
fread(&integer, sizeof(int), 1, fp);
printf("前回から%dバイト後のデータ: %d\n", pos, integer);
pos = sizeof(int) * 4;
fseek(fp, 0 - pos, SEEK_CUR);
fread(&integer, sizeof(int), 1, fp);
printf("前回から%dバイト前のデータ: %d\n", pos, integer);
fclose(fp);
}
int main()
{
const char *file = "C:\\test.dat";
Write(file);
Read(file);
getchar();
}
C:¥test.datに保存しました。 先頭から8バイト目のデータ: 3 前回から0バイト後のデータ: 4 前回から12バイト後のデータ: 8 前回から16バイト前のデータ: 5
サンプルコードで作成されるバイナリファイルは1~10の整数を順番に書き込んだだけのものです。
32ビット環境ではint型は4バイトのサイズなので、先頭から0バイト目は1、4バイト目は2…という値が取得できます。
fseek関数
-
int fseek(
FILE *stream,
long offset,
int origin
); -
ファイルストリームstreamのファイル位置指示子をoriginを基準にoffsetバイト移動する。
戻り値は、正常終了時に0。
エラー時は0以外を返す。
第二引数offsetは、基準となる位置からの相対的な位置をバイト数で示します。
正数(プラス)なら後方、負数(マイナス)なら前方に移動します。
第三引数originは第二引数の基準となる位置を示す以下の定数を指定します。
- SEEK_SET
- ファイルの先頭。
- SEEK_CUR
- 現在の位置。
- SEEK_END
-
ファイルの終端。
バイナリモードでは指定してはならない。
サンプルコードでは、まずfseek関数の第三引数にSEEK_SETをセットし、ファイル先頭から8バイト目のデータを読み取っています。
今回のファイルデータはint型で「1,2,3,…,10」という並びなので、先頭から8バイト目は「3」となります。
fread関数でデータを読み取ると、ファイル位置は読み取ったデータの分だけ後ろにずらされます。
次のfseek関数では第三引数にSEEK_CURを指定し、位置の指定には「0」を指定しています。
現在のファイル位置から0バイト後ろというのはつまり移動しないということです。
(つまり、このfseek関数は何もしていません)
「4」を読み取った後、つまり「5」の位置から12バイト後ろのデータは「8」になります。
(12バイト ÷ 4バイト(int型サイズ) = 3個後ろのデータ)
「9」の位置から16バイト前のデータは「5」となります。
(16バイト ÷ 4バイト = 4個前のデータ)
シーケンシャルアクセスの場合、不要なデータを読み捨てることで「ファイル位置を後ろに移動させる」ことはできますが、「ファイル位置を前に戻す」ということはできません。
前の位置にあるデータが欲しい場合は先頭から読み直すしかないのですが、fseek関数を使えば「今の場所から○バイト前/後」にファイル位置をセットできます。
ただし、ファイルの構造が分からないと正しくデータを読み取ることはできません。
ファイルのどこにどのようなデータが何バイト入っているかを把握しておくか、それを知る方法を用意しておく必要があります。
(例えばどこに何バイトのデータが存在するかをファイル先頭に定義しておくなど)
バイナリモードのSEEK_ENDについて
fseek関数のファイル位置の基準の指定にSEEK_ENDがあります。
これはファイルの終端位置から相対指定をするものですが、バイナリモードで開いているファイルに対してこれは指定できません。
コンパイラによっては上手く動くかもしれませんが、この動作がサポートされることがC言語規約では要求されていないので意図しない動作となる可能性があります。
テキストモードでのfseek関数
ファイルをテキストモードで開いているとき、fseek関数のoffset(第二引数)とorigin(第三引数)には制限があり、以下のどちらかの条件に従う必要があります。
offsetは0を指定する
バイナリモードではファイル位置を調節するためにoffsetにバイト数を指定していましたが、テキストモードではこのような調節はできません。
つまり、ファイル位置を先頭(SEEK_SET)にするか末尾(SEEK_END)にするかのどちらかの操作しかできません。
(SEEK_CURを指定しても意味がありません)
offsetはftell関数の戻り値を指定する
もう一つ、offsetにはftell関数の戻り値を指定することができます。
-
long ftell(
FILE *stream
); - ファイルストリームstreamのファイル位置子を返す。
ftell関数は、現在のファイル位置を返す関数です。
この関数によって取得した値であればoffsetに指定することができます。
この場合、originには必ずSEEK_SETを指定します。
//読み込むテキストファイルには
//ABCDEFGHI...の文字列があるものとする
FILE *fp;
fopen_s(&fp, "C:\\test.txt", "r");
//エラー処理
//...
char str1[3];
char str2[3];
char str3[3];
//先頭二文字(AB)を読み取り
fread(str1, sizeof(char), 2, fp);
str1[2] = '\0';
//「AB」まで読み取った時点のファイル位置を保存しておく
long pos = ftell(fp);
//次の二文字の読み取り
fread(str2, sizeof(char), 2, fp);
str2[2] = '\0';
//ファイル位置を戻す
fseek(fp, pos, SEEK_SET);
//次の二文字の読み取り
fread(str3, sizeof(char), 2, fp);
str3[2] = '\0';
printf("%s\n", str1); //AB
printf("%s\n", str2); //CD
printf("%s\n", str3); //CD
このコードは三回の読み取りが行われているので、何もしなければ先頭から「AB」「CD」「EF」が変数に格納されますが、fseek関数で以前の位置にファイル位置を戻しているので、同じ値が二回読み取られています。
つまりテキストファイルに対しては
- ファイルの先頭
- ファイルの末尾
- ファイルの読み書きによって移動したことのある位置
(ftell関数でその位置を取得している場合)
の三通りのアクセスのみが可能ということです。
ファイルをバイナリモードで開いている場合、ftell関数の戻り値はファイルの先頭からのバイト数です。
この値を元にfseek関数で任意の位置にファイル位置を移動させることも可能です。
なお、fread関数はファイルの現在位置から指定したバイト数のデータを読み取る、という関数に過ぎません。
文字列として値を読み取った場合、その終端にNULL文字が含まれていなければ不正な文字列となります。
ちなみにfgets関数は文字列を取得するための関数なので、自動的に末尾にNULL文字が付加されます。
改行コードの取り扱い
Windows環境では、改行コードは実は二文字(2バイト)で表現されています。
MacOS(UNIX、Linux)環境では、改行コードは一文字です。
(古いMacOSでも一文字ですが、コードの種類が異なります)
| OS | 改行コード | 16進数 |
|---|---|---|
| Windows | CR+LF (\r\n) |
0D 0A |
| Mac OS X(UNIX、Linux) | LF (\n) |
0A |
| Mac OS 9以下 | CR (\r) |
0D |
例えば、「ABC(改行)DEF」という文字列をWindowsとMacOSのテキストエディタで作成するとします。
それらをバイナリデータとして表示すると以下のようになります。
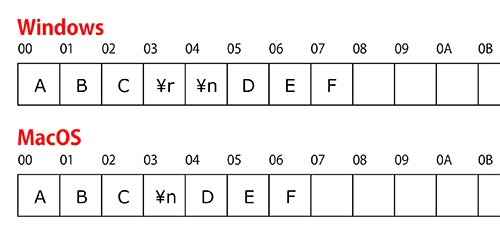
今までのサンプルコードでは、文字列の改行はすべて\nを用いてきましたが、テキストモードで開いているファイルに対して\nはOS固有の改行文字と相互変換されます。
つまりWindows環境ではファイルの読み取りの際に「\r\n」は「\n」に、書き込みの際に「\n」は「\r\n」に自動的に変換されます。
ただし変換されるのはテキストモードで開いた場合のみで、バイナリモードで開いた場合は変換は行われません。
何が問題か
MacOSで作成したテキストファイルを、Windowsでバイナリモードで開いた時、改行コードを二文字として扱ってしまうとデータがズレてしまいます。
上記の図の例では、「D」を取得しようと先頭から6文字目を指定しても、実際に取得されるのは「E」となります。
もちろんOSが逆の場合でも問題は発生します。
「現在のファイル位置から『\n』までを一行とみなし文字列配列に保存する」というようなコードだと、Windowsで作成したテキストを読み込むと配列の最後に「\r」という不要なデータが含まれてしまいます。
さらに、MacOS9以前に作られたテキストだと改行コードを検出できません。
バイナリモードとテキストモード、さらに各OSでの改行コードの違いに注意しないと思ったように動作しない可能性があります。